API与爬虫
2019年03月27日 · 1205 · 6 min好久没写东西了,最近看书看的比较多,而且我不喜欢实体书,所以我会去一些电子书网站下载电子书。做网站总归是要赚钱的,所以广告啥的我都能接受,但是文件下载得方便点啦,别我要点四五次才能下载我需要的东西,这太烦了。
本着能省一点时间就省一点时间的原则,花了几个小时撸了个轮子,其实我什么都没做,只是把好几个api整合到了一起。(所以说嘛,世界上一切都是免费的,只不过有些人愿意氪金而另一些人则愿意肝。
# 需求
看到想要下载的电子书,可以毫不费力地下载电子书,最好直接推送到我的设备上。
# 正常玩家
我常去的电子书网站是小书屋,里面的书质量蛮高的,但是下载起来蛮麻烦的。
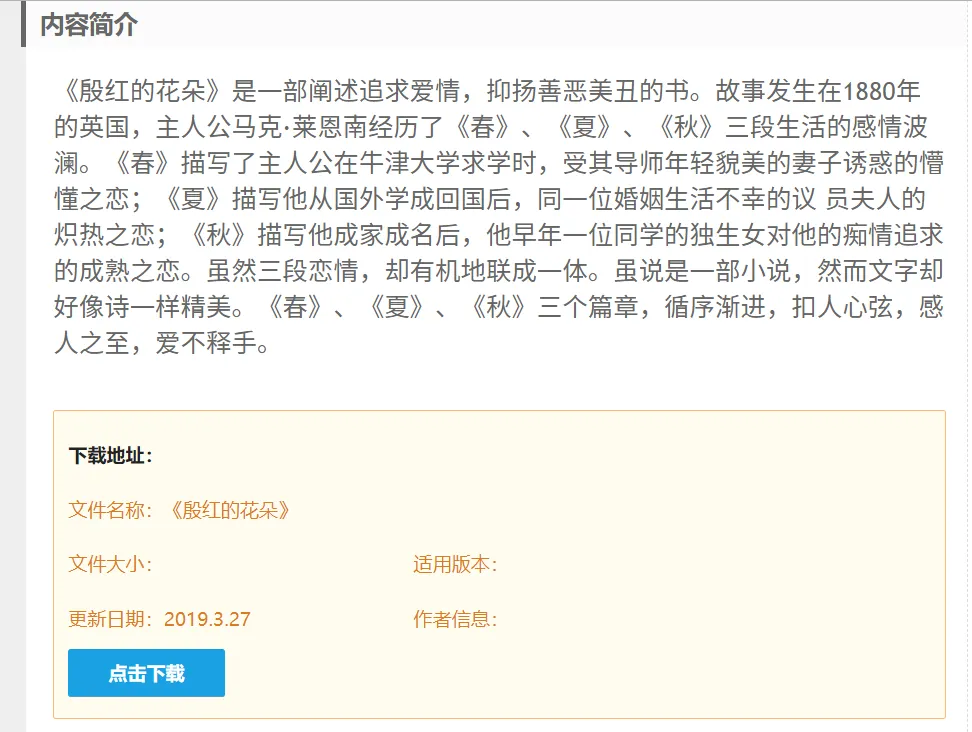
第一步
进入电子书详情页,稍微往下拉就有点击下载。
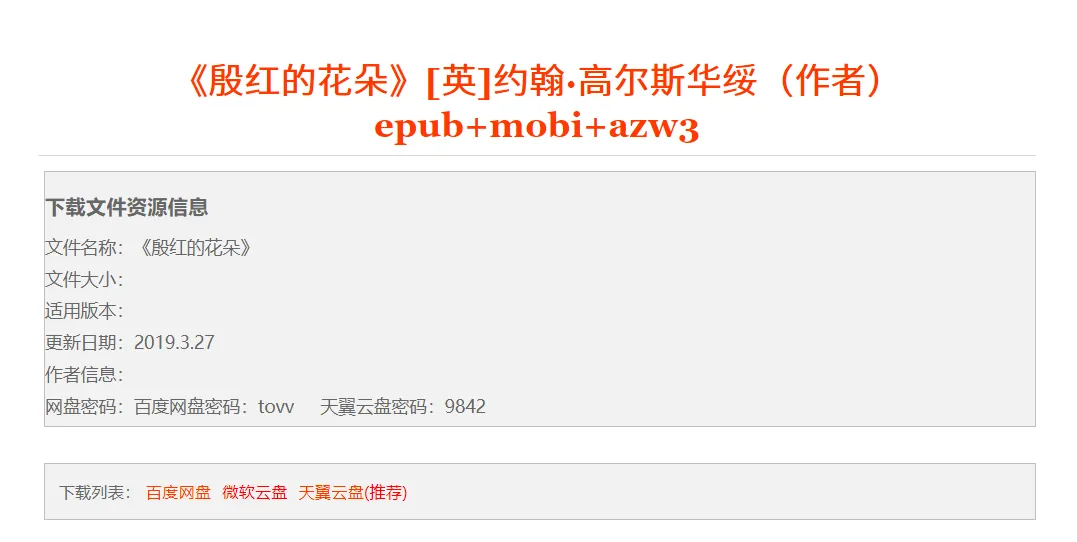
第二步
会进入下载页面,这时候会给出好几个下载方式,但是唯独没有直接下载。
第三步
我是百度黑,所以它家的链接能不点开就不点开,我们先从微软云盘开始把。
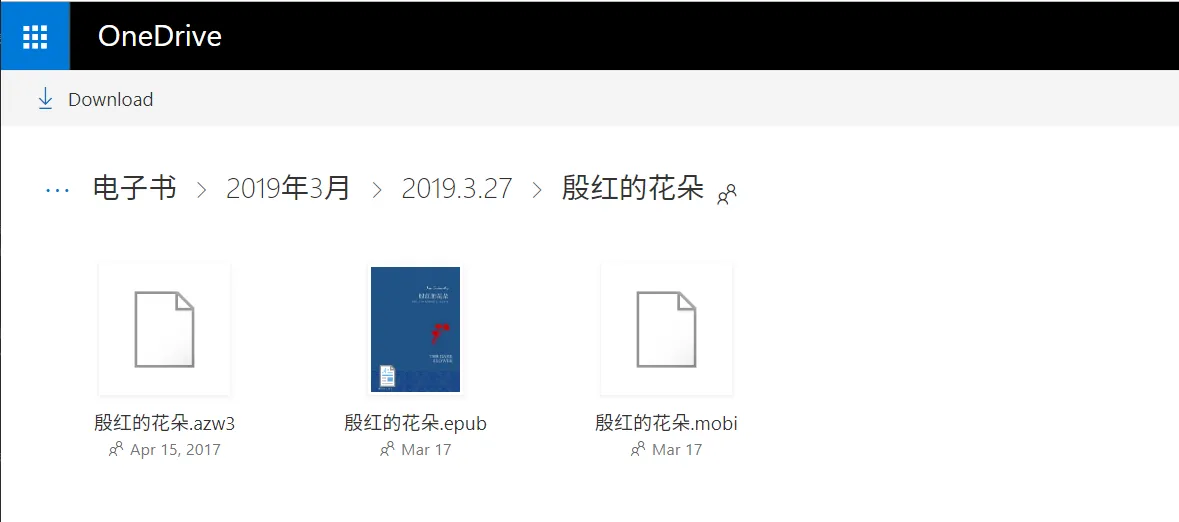
点击进入后会出现一个这样的页面,这里让我称赞下小书屋的站长,真的太优秀了,每次都会做好不同的格式再上传。
第四步
这里我就选择自己需要的文件下载即可。也就是说我下载一本书需要至少跳转4个页面,并且还没算上网络不好onedrive打不开的情况。
# 爆肝玩家
我先直接放结果吧,视频在youtube 需要翻墙观看:
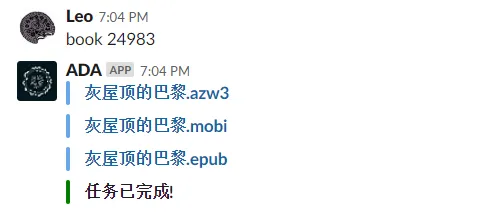
基本达到了我的预期目标,说几个不达标的地方,我一开始弄的时候打算直接复制链接到slack 发送过去就好了,但是slack bot 在处理带斜杠命令传递的时候似乎有些问题,数字小于21291的也无法下载,因为在这之前的书籍站长没有使用OneDrive分享。有空再debug吧,现在这样也基本完善了。
找到一本书后记住number,然后发送给slack bot基本上几秒后就会给我下载链接,点一下就可以下载了。(直接推送进我的手机也不是不可以,就是得和iCloud整合,而iCloud出了名的难搞,我就不折磨自己了。
这个做完了小功能后其实我有打算将整个站爬下来的,但是,又有什么用呢? 我又看不完这些书,要是最后弄得站长直接关站那岂不是搬石头砸自己的脚。(新的书就不会有了
以下部分基本算是记录,算不上教程吧,毕竟我没打算将全部api公布,要不然小书屋的站长要暴捶我了。
分解步骤
1爬取小书屋详情页以获取OneDrive分享链接
2分享链接转换成直链
3分段组合成可直接下载的链接
4推送到slack
话不多说,直接看代码吧
获取分享链接
这一部分是获取下载详情页面的微软云盘链接的。
url = r'%s' % cmd1
headers ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
dl = re.findall(r'百度网盘</a><a href="(.+?)" target="_blank">',html)
dl = dl[0]
转换成直链
这一步的作用是将微软云盘的分享链接转换成直接下载链接,这部分内容我不打算分享,因为这不是我自己的接口,是一个私人接口,所以不可以滥用。(用心的人总能找到的
dl1 = drectL+dl
url = r'%s' % dl1
headers ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
html2 = res.read().decode('utf-8')
分组
转换好的分享链接直接点开是这样的。

一堆乱七八糟的东西,但其实就是文件id和名称还有authkey都在这个页面。
下面的代码就是去爬微软云盘分享直链的内容将整个文件夹分成一个个文件,由于中文的括号与空格会导致 链接出问题,所以统统删掉,并且获取authkey在后面整个到链接里。
url = r'%s' % html2
headers ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
html1 = res.read().decode('utf-8')
dirname = re.findall(r'<Name>(.+?)</Name>',html1)
directlink = re.findall(r'<ResourceID>(.+?)</ResourceID>',html1)
filename = re.findall(r'<RelationshipName>(.+?)</RelationshipName>',html1)
filename1 = []
for sx in filename:
sx=sx.replace("(","")
sx=sx.replace(")","")
sx=sx.replace(" ","-")
filename1.append(sx)
del directlink[0] #去头
filename1 = filename1[:-1] #去尾
key1 = re.findall(r'authkey=(.+?)$',html2)
key2 = key1[0]
推送
数据都有了整合下就好了,这里有我今天学到python的一个新功能:zip。可以将多个变量传入for in,一对一对输入。灰常好用。
for (url,name) in zip(directlink ,filename1):
attachment = json.dumps([
{
"title": name,
"title_link":"https://storage.live.com/items/"""+url+"""?.&authkey="""+key2+"",
"color": '#68A8EB',
},
])
slack_client = SlackClient('<your-token>')
slack_client.api_call(
"chat.postMessage",
channel=channel,
attachments=attachment)
# 总结
真的是应了那句话“你只有非常努力,才能看起来毫不费力。”这个脚本大概只能每次给我省下几分钟罢了,而我一个月也没多少次找新书。
敲代码很枯燥,但是造轮子很好玩,新学了一个函数很开心。
-EOF
标签 :
版权声明 :
本文由 SaltyLeo 撰写,如内容有误,请留言反馈。转载或引用本文时请遵守 CC BY-NC-SA 协议,必须署名、非商业性使用并且以相同方式共享!评论 :
阅读更多 :


整理更新一下家里 Home-Dev 的网络升级吧。

一个超牛掰的下载工具
解决单用户模式重置密码的漏洞
对象存储服务(Cloud Object Storage,COS)是面向企业和个人开发者提供的高可用,高稳定,强安全的云端存储服务。

想要安全的激活Windows系统,自建KMS服务器是最好的选择。
 中文
中文 English
English Français
Français Deutsch
Deutsch 日本語
日本語 Pу́сский язы́к
Pу́сский язы́к 한국어
한국어 Español
Español