使用 Flask 为腾讯云对象储存搭建前置缓存服务器
2022-12-17 · 95806 · 2 min
# 前言
相信大部分人看到这个标题都是一脸懵逼吧,我一开始也并没有想要做这个的,但是手边并没有趁手的工具,只能自己动手丰衣足食了。
下文我会详细解释我的工作流、我理解的前置缓存服务器以及这和腾讯云对象储存有什么关系。
# 我的工作流
再写本站文章的时候,我需要使用图片让文章图文并茂,这里我使用的是Windows自带的截图工具和PicGo 图片上传工具。
一开始我将图片上传到腾讯云对象储存,一切都工作正常,但渐渐的,本站流量越来越多了,在十一日达到顶峰,一天的流量就有8G,而对象储存免费容量只有10G每月。
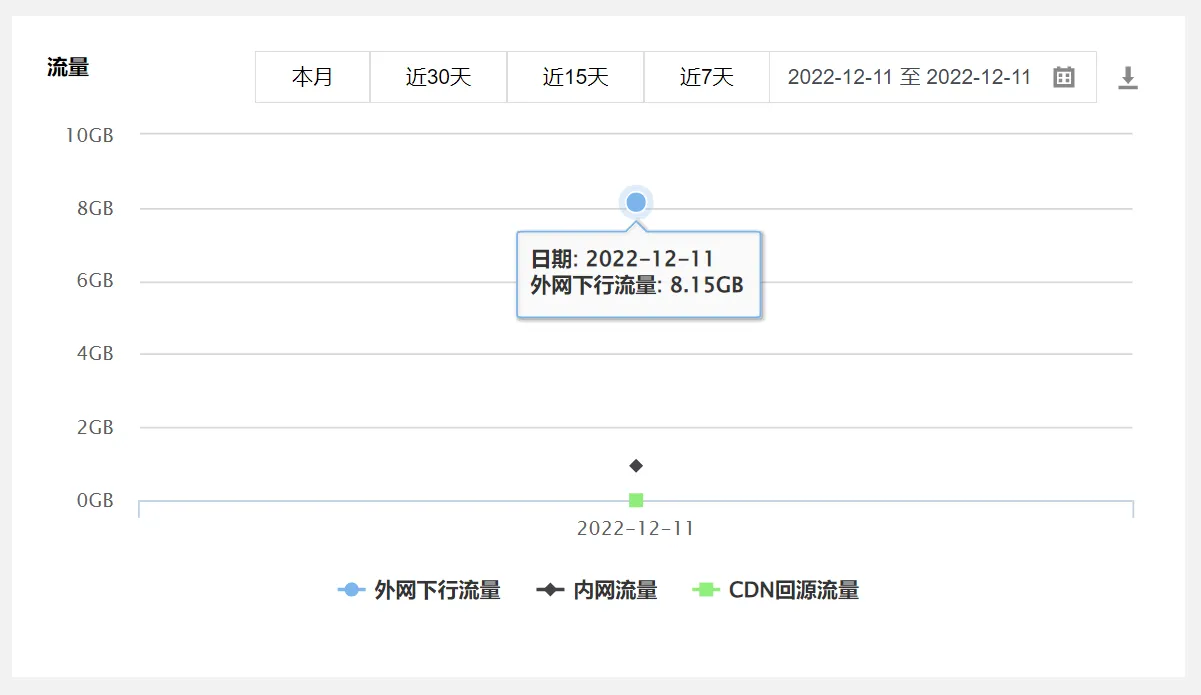
不出所料对象储存的流量一下就超限了,如果放任不管的话,这将会持续不断地耗费我大量的金钱。
# 优化步骤
首先,我检查了一下,确实就是因为图片文件太多,每篇文章内都有好几张,然后都是高清版本的,所以文件大小都比较大。
1、转移文件到Cloudflare
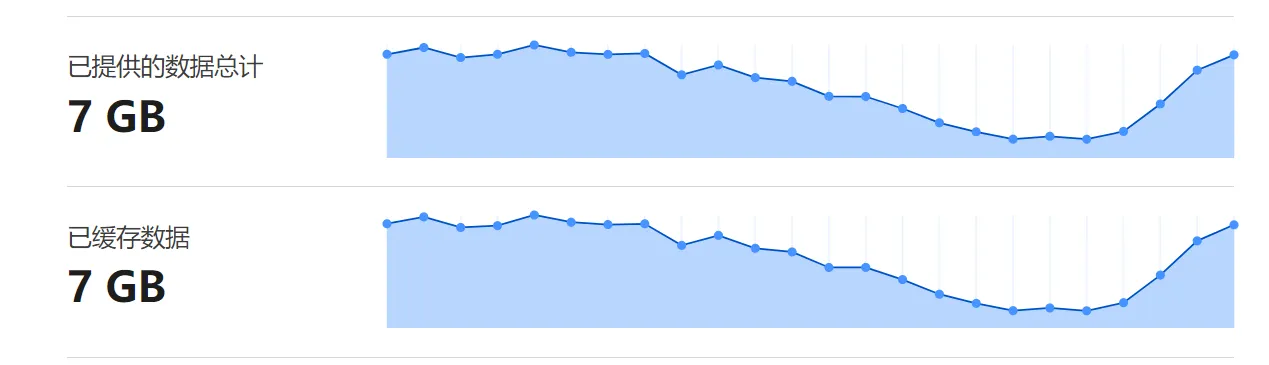
所以我将所有的图片文件都转移到使用了 CloudFlare 代理的站点,部署了新的域名,这样所有的图片访问就会请求到 CloudFlare ,而它对于我这样的免费党来说就可以节省很多流量费用。下图是部署后24小时的流量数据,和对象储存流量相差不大。
2、优化 PicGo 工作流
但这又带来了新的问题:我是使用 PicGo 将图片上传到腾讯云对象储存的,但我现在将文件转移了,虽然我的上传流程不变,但新的图片并不会自动同步到 CloudFlare 的缓存站点中。
一开始我看到 PicGo 有针对此场景的 SFTP 上传插件。但是一通测试下来,不是503报错就是5OO报错,没有一次是正常的。
虽然我可以每次编辑完文章手动拉取一下对象储存的整个文件夹到缓存站点,但这样还是太不优雅了。
所以最后我用 Flask 写了一个简单的前置缓存服务,用来给缓存站点增加点灵魂。下面的代码并不可以直接复制粘贴使用,只是阐述个思路供诸君参考。
from flask import *
import os,requests
app=Flask(__name__,static_url_path='/static/')
app.secret_key = 'xxxxxxx'
def http_status(arg):
try:
html = requests.get(arg)
code = html.status_code
return code
except:
pass
def urldownload(url,filename=None):
down_res = requests.get(url)
with open('./static/img/%s'%filename,'wb') as file:
file.write(down_res.content)
@app.route('/')#首页
def index():
return'Silence is gold.'
@app.route('/img/<aa>')
def re_img(aa):
if os.path.exists('/root/jt/static/img/%s'%aa) == False:#文件不存在
if http_status('https://myqcloud.com/img/%s'%aa) != 200:#对象储存也不存在
return 'This file was not found.'
else:
urldownload('https://myqcloud.com/img/%s'%aa,filename=aa)
return send_file('./static/img/%s'%aa,as_attachment=True)
else:
return send_file('./static/img/%s'%aa,as_attachment=True)
if __name__=="__main__":
app.run(host="0.0.0.0", port=8833)
# 后记
各种互联网基础设施提供商,在市场上盘根错节根深蒂固,没有人会反对他们的定价,而有些新晋厂商却敢于挑战它们。GitHub上的陈年老仓库也有些都不能用了,需要注意辨别。 这篇文章我写出来,并不是为了教什么,只是想表达自己动手丰衣足食才是决绝问题的唯一出路。





 中文
中文 English
English Français
Français Deutsch
Deutsch 日本語
日本語 Pу́сский язы́к
Pу́сский язы́к 한국어
한국어 Español
Español