私が作成した本のメタデータベースAPIを共有する。
2024年07月14日 · 7 · 4 min
# 前の記事
国内図書界最大の【豆豆読书】がパブリックAPIをシャットダウンした後、多くの書籍メタデータを削ぎ掛けプラグインが役割を失ったので、私自身は既存のリソースを使って新しいAPIサービスを作成しました。アドレス:https//book-db-v1.saltyleo.com/
この記事のテーマは、私が作った新しいものを共有することです。
# 使用方法は
端点URL: https://book-db-v1.saltyleo.com
请求方法: GET
响应格式: JSON
このリンク、:https://book-db-v1.saltyleo.com/?keyword=刘慈欣を直接クリックすると、開発者のためにJSONを直接解析することができる“Liu Cixin”に関するトップ10の書籍情報を取得できます。
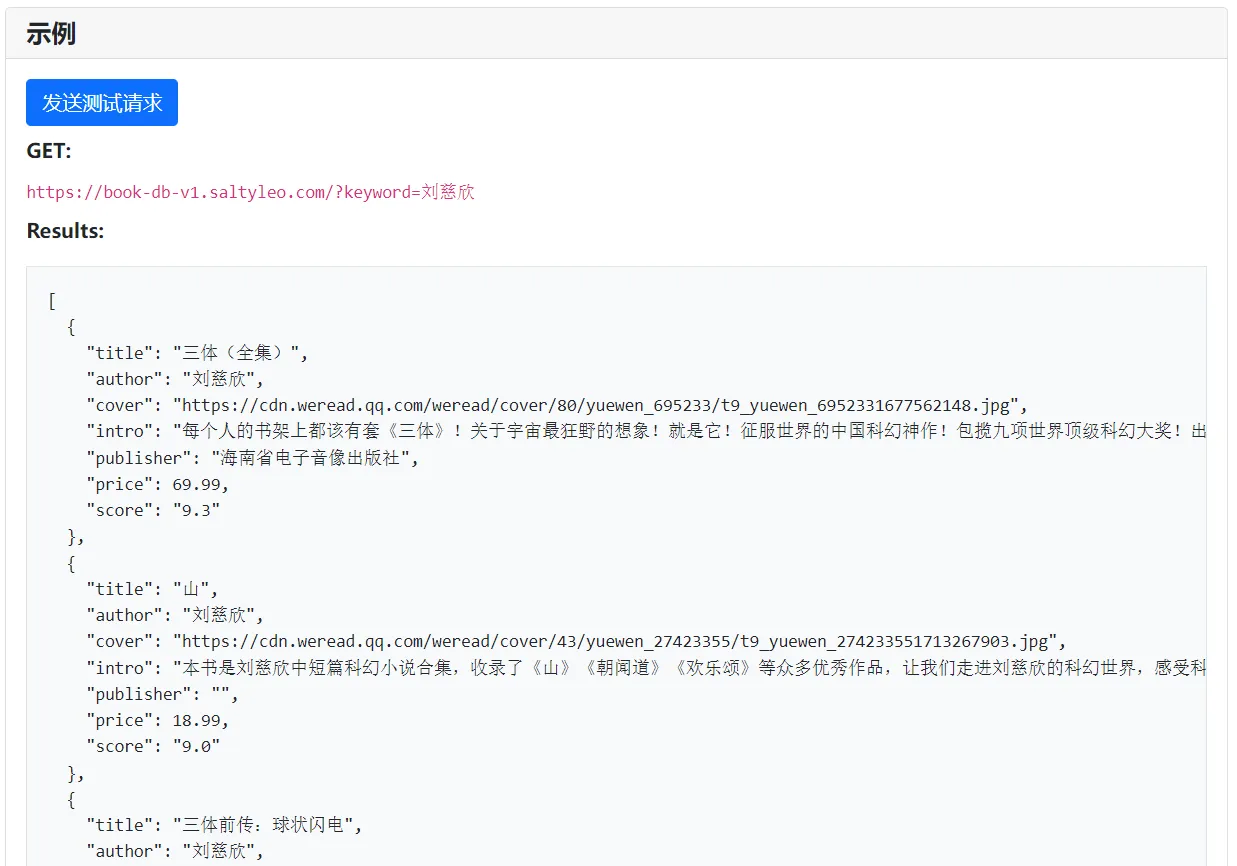
開発者ではなく、ウェブ上でお気に入りの電子書籍を見つけたい場合は、私の本棚に直接行く方が速くなります:SaltyLeo的书架
# 何をしたの?
私は電子書籍の検索サイトをしていなかった、データを収集する過程で、多くの電子書籍のウェブサイトの本の情報は、しばしば名前であることがわかった。手動で検索エンジンを検索するのは悪くないし、非効率なので、本の情報を理解するためにこのAPIを作りました。
すべてが作られたので、単独の喜びは他の喜びよりも悪くないと思い、単にそれを公開しました。API呼び出しを提供する理由は、自作のブックステーションを行いたい場合、または新しいスクラッチプラグインを開発したい場合は、APIを直接呼び出してデータを取得し、多くのデータ収集、データ処理時間を節約し、JSONを直接解析してプロジェクトに置くことができます。
これはAPIの最初のバージョンなので、データは少ないです。徐々に追加します。そして、私はまだビッグデータの分野に非常に興味があります。このAPIは安定した反復と長期的な運用になります。
バックエンドはCloudFlare Workerデプロイメントに基づいており、コストはほぼゼロです。もちろん、高い請求書を避けるために、私はCloudFlareを通じて最大QPSを設定しました。つまり、毎秒10回のアクセスを制限します。これは電子書籍のスクラップの一般的な数に十分です。1分で600冊の本を処理することができ、小さなデータは一瞬で処理できます。数十万、数百万のコピーがある場合は、IPプールやその他のマルチスレッドクローラ技術を使用できます。とにかく限界に達したら、さらに制限速度を😏にします。
# あとがき
AIの恩恵により、以前は学習を深く理解しなければならなかったことが、今では非常に簡単になります。学習速度は指数関数的に増加しており、JSのように私はまだそれを理解していませんが、AIが私が必要とする機能を書くのを助けることができないことを妨げません、私は低コードとコードなしまたは信頼性が低いと感じ、AIによって生成されたコードスニペットは常にさまざまなバグがあり、手動で修正する必要があります。
最後に、私はいくつかの小さな仕事をしただけで、インターネット上に散らばっているデータを少し整理し、要約し、言及する価値がない。
タグ :
著作権に関する注意事項 :
この記事はSaltyLeoによって書かれました。誤りがある場合は、コメントでフィードバックをお願いします。この記事の転載や引用を行う場合は、CC BY-NC-SA ライセンスに従う必要があります。帰属表示、非営利利用、同一条件の共有が必要です!コメント :
続きを読む :


現在市販されている車は基本的にチューブレスタイヤであり、アトミックタイヤと呼ばれています

MindMaster Pro マインド マッピング ツールのアクティベーション コードを無料で入手
オイル モンキー スクリプトを使用して、ネットワーク全体のすべてのプラットフォームから音楽をダウンロードする

ワンクリック配備サーバー環境

便利なオンライン ツールを共有しましょう。
 日本語
日本語 中文
中文 English
English Français
Français Deutsch
Deutsch Pу́сский язы́к
Pу́сский язы́к 한국어
한국어 Español
Español