i-book.in的自动化更新(Python爬虫)
2019年11月22日 · 1128 · 3 min# 自动化脚本
最近重新设计了一下 i-book.in,把自动化脚本给更新了,具体的代码我就不贴了,GitHub上全都有。
Github:Ebook-crawler
因为不涉及核心数据只是爬虫源码,所以我就把它发到GitHub上了,有兴趣慢慢爬数据的可以git到自己的服务器使用,懒得弄得就直接用 i-book.in 就可以了。
具体实现的方法还是蛮简单的:
1.获取图书的名称。
2.根据名称去Algolia检索,确认是否有这本书。如果有就跳过,如果没有就解析并下载。
3.下载完成后将数据上传到ipfs网络,并解析hash。
4.根据解析的图书数据和ipfs的hash数据,组合成Algolia能接受的json格式字符。
5.将json上传到Algolia,这样数据库就有了这本书了,下次碰到就不会再下载了。
# 反爬虫
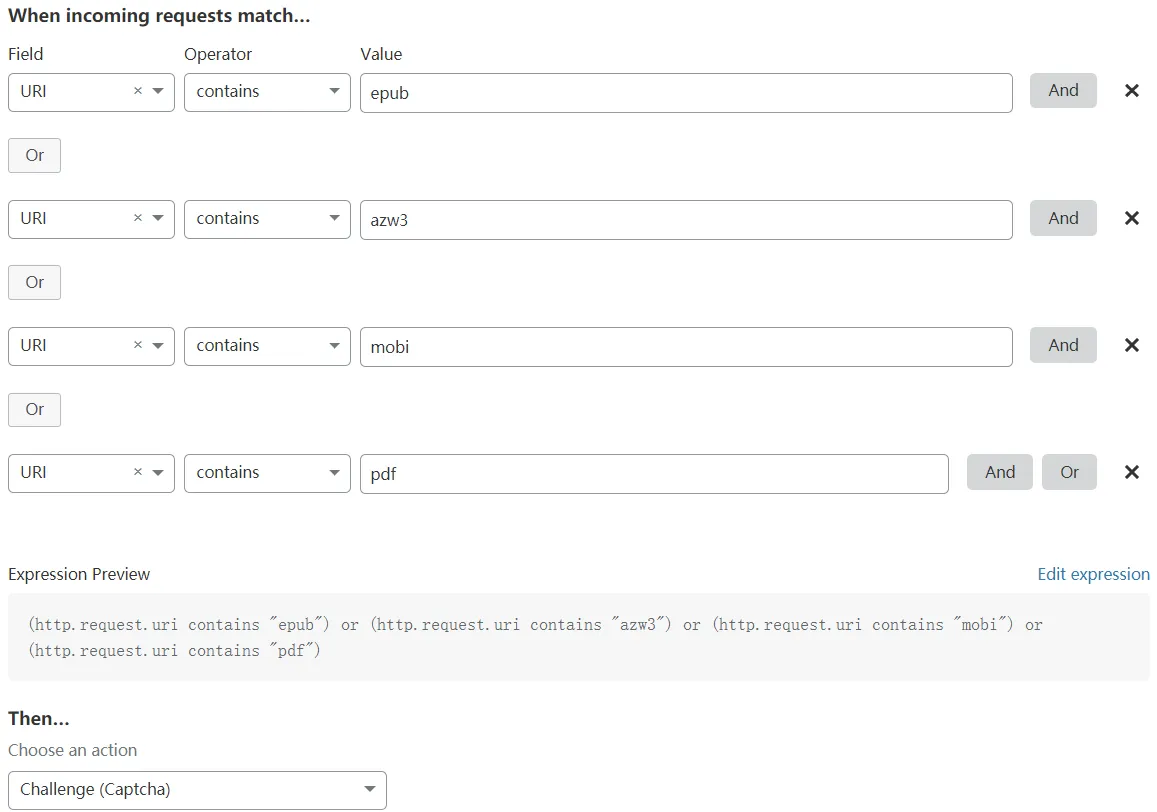
不管是啥网站都会有爬虫的,所以在对博客套了CF盾后我给i-book.in也用上了CF,并且对下载电子书的操作添加了反爬虫措施,就是在CF的防火墙规则内设置,将电子书的后缀格式作为关键词,有这些关键词就触发人机验证。具体的设置如下图。
# 英文原版书
除了恩京的书房,我最近还在爬取英文原版书,虽然不一定看得懂,但看看也能学点英文不是么,最主要是爬数据很好玩啊~
这个网站还在爬取中,具体的爬取代码等我debug完了,也放到GitHub上,不得不吐槽一下,外国人给书起名字怎么都辣么奇怪,全是各种标点符号,我都要replace掉,要不然就会创建文件夹失败,导致后续的下载全部失败。
挂机下载了一下午,一共下载了3473本书,另外还有17本书错误,这17本我也懒得debug了,好像还是特殊符号问题。
# Algolia账户合并
这个英文原版书全部整合到一个数据库后,数据库内的数据将超过1W条,所以在后端上i-book.in需要同时使用多个Algolia账户同时搜索。
所以合并账户要提上日程,php我又不会,所以打算重新写一个python的web服务,内置多个Algolia账户用来扩容索引,或者直接上sql,但我sql也不会(菜鸡就是我没错了。
-EOF-
标签 :
版权声明 :
本文由 SaltyLeo 撰写,如内容有误,请留言反馈。转载或引用本文时请遵守 CC BY-NC-SA 协议,必须署名、非商业性使用并且以相同方式共享!评论 :
阅读更多 :


抽出空来聊一聊这段断更时间发生了啥。

手动结束Gunicorn 进程以及重启进程

在删除相册的时候还是有点恻隐之心的,毕竟辣么多年的照片要全删掉。

本文主要内容为编译安装带有FTS5扩展的Sqlite3

本文主要内容是关于日常使用 ChatGPT 时产生的一些思考,以及对其未来的展望。
 中文
中文 English
English Français
Français Deutsch
Deutsch 日本語
日本語 Pу́сский язы́к
Pу́сский язы́к 한국어
한국어 Español
Español