i-book.in 자동 업데이트(Python 크롤러)
2019-11-23 · 1075 · 1 min# 자동화 스크립트
최근에 i-book.in 재 설계하고 자동화 스크립트를 업데이트했으며 GitHub에 특정 코드를 게시하지 않겠습니다.
Github:전자책 크롤러
핵심 데이터는 관여하지 않기 때문에 그냥 소스코드를 크롤링하는 것뿐이라서 깃허브로 보냈고, 천천히 데이터를 올리고 싶은 분은 자신의 서버에 활용하시면 되고, 너무 게으르면 바로 i-book.in를 사용하시면 됩니다.
구체적인 구현 방법은 매우 간단합니다.
1. 책의 이름을 가져옵니다.
2.Algolia의 이름으로 이동하여 책이 있는지 확인합니다. 가지고 있다면 건너 뛰고, 없으면 구문 분석하고, 다운로드하십시오.
3. 다운로드가 완료되면 데이터를 IPFS 네트워크에 업로드하고 해시를 구문 분석합니다.
4.파싱된 장부 데이터와 ipfs 해시 데이터를 기반으로 알골리아가 받아들일 수 있는 JSON 형식의 문자로 결합한다.
5.데이터베이스에 책이 있고 다음에 책을 발견할 때 다운로드하지 않도록 json을 Algolia에 업로드합니다.
# 안티 크롤러
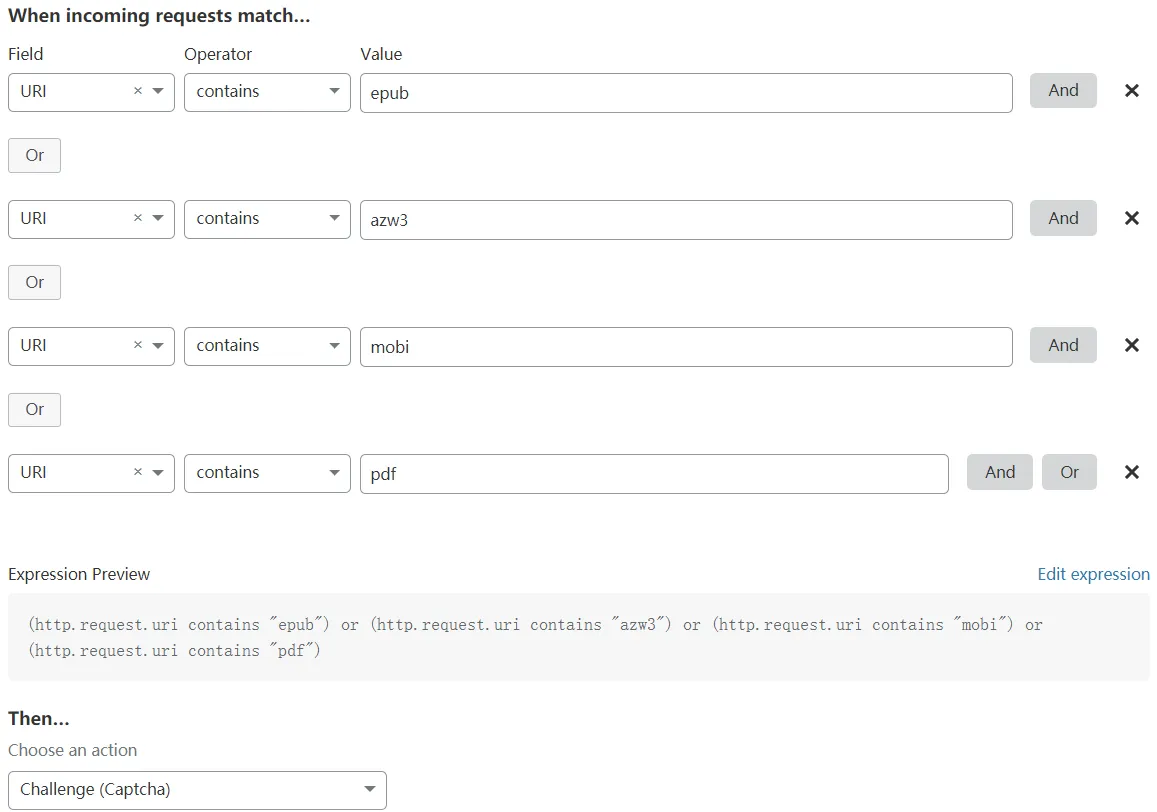
웹 사이트에 크롤러가 무엇이든 상관없이 블로그에 CF 쉴드를 설정 한 후 i-book.in 에도 CF를 사용하고 전자 책 다운로드 작업에 크롤러 방지 조치를 추가했습니다 (즉, CF의 방화벽 규칙 내에서 설정), 전자 책의 접미사 형식을 키워드로 설정하고 이러한 키워드는 보안 문자를 트리거합니다. 다음 그림에서는 특정 설정을 보여 줍니다.
# 영어 원작
은징의 공부 외에도 최근에 영어 원문을 크롤링하고 있는데 이해할 수는 없지만 영어를 보면 영어를 배울 수 있는데 가장 중요한 것은 등반 데이터가 매우 재미 있다는 것입니다 ~
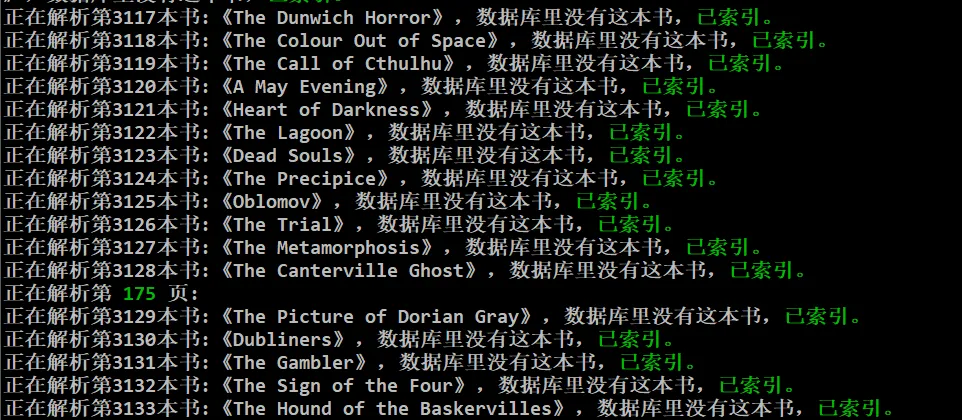
이 웹 사이트는 여전히 크롤링 중이며, 특정 크롤링 코드 등은 내 디버그가 완료되고, GitHub에 올려 놓고, 외국인이 책의 이름을 매운 이상한 방법, 모든 종류의 구두점, 교체해야합니다, 그렇지 않으면 폴더 생성이 실패하여 후속 다운로드가 모두 실패했습니다.
오후에 총 3473 권의 책을 다운로드했는데 17 권의 책 오류가 있었는데, 마치 특수 기호 문제 인 것처럼 버그를 괴롭히지 않았습니다.
# 알골리아 계정 합병
이 영어 원작이 모두 하나의 데이터베이스에 통합되면 데이터베이스의 데이터가 1W를 초과하므로 백엔드 i-book.in 에서는 동시에 여러 Algolia 계정을 사용하여 검색해야 합니다.
그래서 계정 병합은 의제에 있고, PHP는 그렇지 않을 것이므로 파이썬 웹 서비스, 내장 된 여러 Algolia 계정을 다시 작성하여 인덱스를 확장하거나 SQL에서 직접 작성할 계획이지만 SQL은 그렇지 않습니다 (신인 치킨은 내가 옳다.
-EOF-
태그 :
저작권 공지 :
이 글은 SaltyLeo가 쓴 것입니다, 내용에 오류가 있다면 의견을 남겨주세요. 이 글은 CC BY-NC-SA 라이선스를 준수하여 재게시 또는 인용할 때는 필자를 언급하고, 상업적 용도로 사용하지 않아야 하며, 동일한 방식으로 공유되어야 합니다!댓글 :
더 읽기 :


WordPress 위젯 "기능"에서 WordPress.org 링크 제거
Creative-Commons-Configurator를 사용하여 wordpress 블로그 프로그램에 대한 저작권 계약을 추가하십시오.
마이닝 풀 쿼리 페이지의 데이터를 정기적으로 가져와서 저장하려면 직접 크롤러를 만들어야 합니다.

이 기사는 상세한 Mastodon 설치 튜토리얼입니다.
가정용 장비의 상업적 사용에 대한 약간의 탐구
 한국어
한국어 中文
中文 English
English Français
Français Deutsch
Deutsch 日本語
日本語 Pу́сский язы́к
Pу́сский язы́к Español
Español