파이썬 크롤러 만들기
2018-10-18 · 941 · 1 min# 원인
저는 최근에 모네로를 채굴하고 있으며 지갑 데이터를 모니터링해야 합니다. 하지만 풀은 지난 '24시간' 동안의 데이터만 보관하고, '이번 달에 총 얼마를 팠는지' 등 과거 기록을 봐야 한다면 할 수 없다. 그래서 직접 크롤러를 만들고 마이닝 풀 쿼리 페이지의 데이터를 주기적으로 크롤링하여 저장해야합니다.
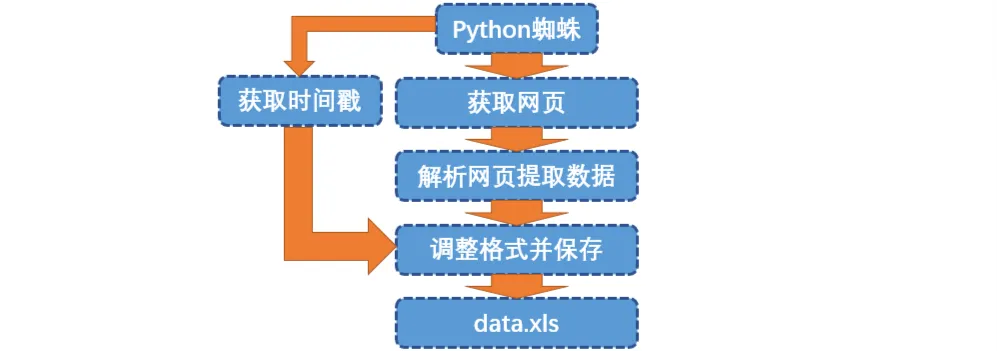
# 순서도
# 준비
내가 사용하고있는 시스템은 'python3'과 함께 제공되는 WSL-Ubuntu 18.04이며 다음 명령을 사용하여 설치하지 않은 경우 프로젝트는 {% label success@xlrd, xlwt, xlutils%} 라이브러리를 사용해야합니다.
pip3 설치 xlrd xlwt xlutils
'python3' 또는 'pip3'이 설치되지 않은 경우 다음 명령을 사용합니다.
sudo apt-get python3 설치
sudo apt-get python3-pip 설치
# 코드 구현
시간 확보
Excel을 저장할 때 시간별로 데이터를 정렬하려면 먼저 타임 스탬프를 가져와야합니다.
# 코딩=UTF-8
가져오기 시간
지금 = int(round(time.time()*1000))
now02 = time.strftime('%m-%d %H:%M',time.localtime(now/1000))
여기에는 now02의 타임스탬프가 포함됩니다.
페이지 크롤링
크롤러는 먼저 전체 페이지를 가져온 다음 일반 또는 기타 도구를 사용하여 데이터를 필터링합니다.
수입 재
urllib.request 가져 오기
url = r'https://page you need to crawl' #这里我就不把查询页面贴出来了, 따옴표로 묶인 링크 앞에는 http:// 또는 https:// 와야 합니다. 그렇지 않으면 오류가 보고됩니다
headers ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Gecko와 같은 KHTML) Chrome/55.0.2883.87 Safari/537.36'} #模拟浏览器
요청 = urllib.request.Request (url = url, 헤더 = 헤더)
해상도 = urllib.request.urlopen(req)
html = res.read().decode('utf-8') #将文件用utf-8 인코딩
일반 필터링
여기에 다른 정규식을 선택하는 데 필요한 데이터에 따라 필요한 데이터는 0.00000000과 같은 숫자의 문자열이며 그 사이에 다른 문자가 연속으로 4 번 있습니다. (물론 모든 0이 0은 아니지만 0-9 사이의 숫자입니다.)
re1='.*?' # 필러에 대한 욕심 없는 일치
re2='([+-]?\\d*\\.\\d{8})(?! [-+0-9\\.])' # 플로트 1
re3='.*?' # 필러에 대한 욕심 없는 일치
re4='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # 플로트 2
re5='.*?' # 필러에 대한 욕심 없는 일치
re6='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # 플로트 3
re7='.*?' # 필러에 대한 욕심 없는 일치
re8='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # 플로트 4
RG = re.compile (re1 + re2 + re3 + re4 + re5 + re6 + re7 + re8, re. IGNORECASE|re입니다. 도탈)
m = rg.search(html)
m인 경우: #m内就是我需要的4串数字了.
float1=m.그룹(1)
float2=m.그룹(2)
float3=m.그룹(3)
float4=m.그룹(4)
엑셀 읽기
Excel 내에서 지속적으로 데이터를 쓰고 싶기 때문에 데이터가 기록되는 위치를 결정하기 위해 행과 열 데이터를 가져와야 합니다.
xlrd 가져오기
xlrd에서 가져 오기 open_workbook
데이터 = xlrd.open_workbook('데이터.xls') #读取数据
페이지 = len(data.sheets()) #获取sheet的数量
테이블 = data.sheets()[0]#打开第一张表
nrows = table.nrows# 총 행 수를 가져옵니다.
ncols = table.ncols#는 총 열 수를 가져옵니다.
h = table.nrows #将行数保存下来后面写入数据的时候用
편집, 쓰기, 엑셀 저장
소스 파일을 메모리에 복사한 다음 메모리의 데이터를 편집하고 다음 목록 너비를 설정하고 마지막으로 저장합니다.
rexcel = open_workbook("data.xls") # wlrd에서 제공하는 방법을 사용하여 엑셀 파일 읽기
rows = rexcel.sheets()[0].nrows # wlrd에서 제공하는 방법을 사용하여 현재 사용할 수 있는 행 수를 얻습니다.
excel = copy(rexcel) # xlutils에서 제공하는 copy 메서드를 사용하여 xlrd 객체를 xlwt 객체로 변환
table = excel.get_sheet(0) # xlwt 객체의 메서드를 사용하여 조작할 시트를 가져옵니다.
값 = ["1"]
a1=table.col(0) #设置单元格宽度
A1. 너비 = 150 * 20
a2=테이블.col(1)
A2. 너비 = 150 * 20
a3=테이블.col(2)
A3. 너비 = 150 * 20
a4=테이블.col(3)
A4. 너비 = 150 * 20
a5=테이블.col(4)
A5. 너비 = 150 * 20
값의 time1의 경우:
table.write(h,0,now02) # xlwt 객체 쓰기 방법, 매개변수는 행, 열, 값입니다.
table.write(h,1,float1)
table.write(h,2,float2)
table.write(h,3,float3)
table.write(h,4,float4)
Excel.save("data.xls") # xlwt 객체가 저장되어 원본 Excel을 덮어씁니다.
# 요약
스크립트 실행 명령은 python3으로 시작하고 python은 오류를 보고합니다. 스크립트를 실행하기 전에 스크립트 디렉토리에 새 'data.xls'를 만들어 파일을 저장해야 합니다.
관심은 최고의 선생님, 과거에는 파이썬을 배울 때 항상 책을 배열에 내려 놓은 것 같은 느낌이 들었지만 지금은 마음 속에 아이디어가 있고 해결책을 찾고 싶어서이 거미가 있습니다.
이 코드에는 내가 정말로 이해하지 못하는 많은 것들이 있지만, 적어도 지금은 스크립트가 내가 원하는대로 작동합니다. 괜찮은 것 같아요.
전체 코드:
# 코딩=UTF-8
가져오기 시간
xlrd 가져오기
xlwt 가져오기
urllib.request 가져 오기
수입 재
xlrd에서 가져 오기 open_workbook
xlutils.copy에서 가져 오기 사본
OS 가져오기
지금 = int(round(time.time()*1000))
now02 = time.strftime('%m-%d %H:%M',time.localtime(now/1000))
url = r'https://page you need to crawl' #这里我就不把查询页面贴出来了, 따옴표로 묶인 링크 앞에는 http:// 또는 https:// 와야 합니다. 그렇지 않으면 오류가 보고됩니다
headers ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Gecko와 같은 KHTML) Chrome/55.0.2883.87 Safari/537.36'}
요청 = urllib.request.Request(url=url,headers=headers) #模拟浏览器
해상도 = urllib.request.urlopen(req)
html = res.read().decode('utf-8') #将文件用utf-8 인코딩
re1='.*?' # 필러에 대한 욕심 없는 일치
re2='([+-]?\\d*\\.\\d{8})(?! [-+0-9\\.])' # 플로트 1
re3='.*?' # 필러에 대한 욕심 없는 일치
re4='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # 플로트 2
re5='.*?' # 필러에 대한 욕심 없는 일치
re6='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # 플로트 3
re7='.*?' # 필러에 대한 욕심 없는 일치
re8='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # 플로트 4
RG = re.compile (re1 + re2 + re3 + re4 + re5 + re6 + re7 + re8, re. IGNORECASE|re입니다. 도탈)
m = rg.search(html)
m인 경우: #m内就是我需要的4串数字了.
float1=m.그룹(1)
float2=m.그룹(2)
float3=m.그룹(3)
float4=m.그룹(4)
데이터 = xlrd.open_workbook('데이터.xls') #读取数据
페이지 = len(data.sheets()) #获取sheet的数量
테이블 = data.sheets()[0]#打开第一张表
nrows = table.nrows# 총 행 수를 가져옵니다.
ncols = table.ncols#는 총 열 수를 가져옵니다.
h = table.nrows #将行数保存下来后面写入数据的时候用
rexcel = open_workbook("data.xls") # wlrd에서 제공하는 방법을 사용하여 엑셀 파일 읽기
rows = rexcel.sheets()[0].nrows # wlrd에서 제공하는 방법을 사용하여 현재 사용할 수 있는 행 수를 얻습니다.
excel = copy(rexcel) # xlutils에서 제공하는 copy 메서드를 사용하여 xlrd 객체를 xlwt 객체로 변환
table = excel.get_sheet(0) # xlwt 객체의 메서드를 사용하여 조작할 시트를 가져옵니다.
값 = ["1"]
a1=table.col(0) #设置单元格宽度
A1. 너비 = 150 * 20
a2=테이블.col(1)
A2. 너비 = 150 * 20
a3=테이블.col(2)
A3. 너비 = 150 * 20
a4=테이블.col(3)
A4. 너비 = 150 * 20
a5=테이블.col(4)
A5. 너비 = 150 * 20
값의 time1의 경우:
table.write(h,0,now02) # xlwt 객체 쓰기 방법, 매개변수는 행, 열, 값입니다.
table.write(h,1,float1)
table.write(h,2,float2)
table.write(h,3,float3)
table.write(h,4,float4)
Excel.save("data.xls") # xlwt 객체가 저장되어 원본 Excel을 덮어씁니다.
태그 :
저작권 공지 :
이 글은 SaltyLeo가 쓴 것입니다, 내용에 오류가 있다면 의견을 남겨주세요. 이 글은 CC BY-NC-SA 라이선스를 준수하여 재게시 또는 인용할 때는 필자를 언급하고, 상업적 용도로 사용하지 않아야 하며, 동일한 방식으로 공유되어야 합니다!댓글 :
더 읽기 :


gonme 아래에 내장된 스크린샷 도구가 있으며 바로 가기 키만 설정하면 됩니다.
가정용 장비의 상업적 사용에 대한 약간의 탐구

Google 애드센스에 대한 몇 가지 생각과 연구

ChatGPT를 사용하는 가장 쉬운 방법!

수동으로 타이머를 설정하고 V2ray를 다시 시작합니다.
 한국어
한국어 中文
中文 English
English Français
Français Deutsch
Deutsch 日本語
日本語 Pу́сский язы́к
Pу́сский язы́к Español
Español