Pythonクローラーを作る
2018-10-18 · 941 · 2 min# 原因
私は最近Moneroをマイニングしていて、ウォレットデータを監視する必要があります。 しかし、プールは過去「24時間」のデータしか保持せず、「今月合計でどれだけ掘ったか」などの過去の記録を見る必要がある場合、それを行うことはできません。 そのため、自分でクローラーを作成し、マイニングプールクエリページのデータを定期的にクロールして保存する必要があります。
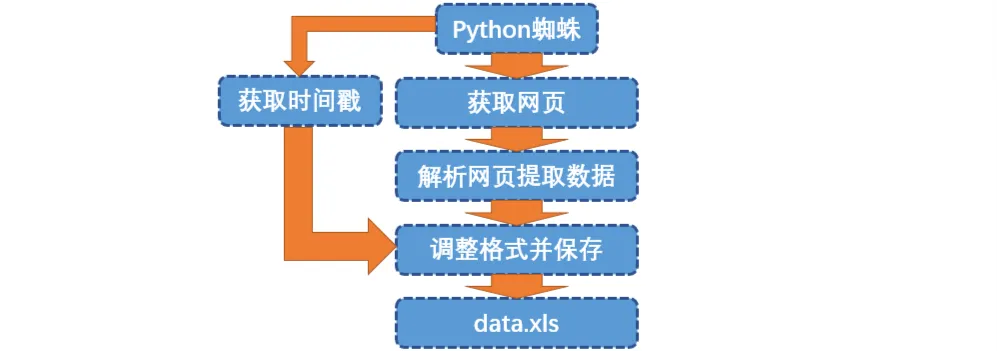
# フローチャート
# 事前準備
私が使用しているシステムは 'python3'に付属しているWSL-Ubuntu 18.04で、次のコマンドを使用してインストールされていない場合、プロジェクトは{%ラベルsuccess@xlrd、xlwt、xlutils%}ライブラリを使用する必要があります。
PIP3 インストール XLRD XLWT XLUTILS
'python3' または 'pip3' がインストールされていない場合は、次のコマンドを使用します。
sudo apt-get install python3
sudo apt-get install python3-pip
# コード実装
時間を取得する
Excelを保存するときにデータを時間で並べ替える必要があるため、最初にタイムスタンプを取得する必要があります。
# コーディング = UTF-8
インポート時間
now = int(round(time.time()*1000))
now02 = time.strftime('%m-%d %H:%M',time.localtime(now/1000))
これには、now02 のタイムスタンプが含まれます。
ページをクロールする
クローラーは、最初にページ全体を取得してから、通常のツールまたは他のツールを使用してデータをフィルタリングします。
インポート再
インポート urllib.request
url = r'https://page あなたはクロールする必要があります' #这里我就不把查询页面贴出来了、引用符で囲まれたリンクの前に http:// または https:// を付ける必要があります それ以外の場合は、エラーが報告されます
headers ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (ヤモリのような KHTML) Chrome/55.0.2883.87 Safari/537.36'} #模拟浏览器
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8') #将文件用utf-8 エンコーディング
通常のフィルタリング
ここで、異なる正規表現を選択するために必要なデータによると、必要なデータは、そのような数字0.00000000の文字列で、間に他の文字を挟んで4回連続しています。 (もちろん、すべて0ではなく、0から9までの任意の数値です。
re1='.*?' # フィラーの非貪欲一致
re2='([+-]?\\d*\\.\\d{8})(?! [-+0-9\\.])' # 浮動小数点数 1
re3='.*?' # フィラーの貪欲でない一致
re4='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # 浮動小数点数2
re5='.*?' # フィラーの貪欲でない一致
re6='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # 浮動小数点数3
re7='.*?' # フィラーの貪欲でない一致
re8='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # 浮動小数点数4
rg = re.compile(re1+re2+re3+re4+re5+re6+re7+re8,re. 大文字と小文字を無視する|re. ドトール)
m = rg.search(html)
mの場合:#m内就是我需要的4串数字了。
浮動小数点数1=M.グループ(1)
浮動小数点数2=M.グループ(2)
浮動小数点数3=M.グループ(3)
浮動小数点数4=m.グループ(4)
エクセルを読む
Excel 内で継続的にデータを書き込む必要があるため、行データと列のデータを取得して、データが書き込まれる場所を決定する必要があります。
XLRDをインポートする
XLRDインポートopen_workbookから
データ = xlrd.open_workbook('データ.xls') #读取数据
page = len(data.sheets()) #获取sheet的数量
table = data.sheets()[0]#打开第一张表
nrows = table.nrows# は行の総数を取得します
ncols = table.ncols# は列の総数を取得します
h = テーブル.n行 #将行数保存下来后面写入数据的时候用
編集、書き込み、エクセルの保存
ソースファイルをメモリにコピーし、メモリ内のデータを編集し、次のリスト幅を設定して、最後に保存します。
rexcel = open_workbook("data.xls") # wlrd が提供するメソッドを使用して Excel ファイルを読み込む
rows = rexcel.sheets()[0].nrows # wlrd が提供するメソッドを使用して、現在利用可能な行数を取得します。
excel = copy(rexcel) # xlutils が提供するコピー方法を使用して、xlrd オブジェクトを xlwt オブジェクトに変換する
table = excel.get_sheet(0) # xlwtオブジェクトのメソッドを使用して、操作するシートを取得します
値 = ["1"]
a1=table.col(0) #设置单元格宽度
a1.幅= 150 * 20
a2=table.col(1)
a2.幅= 150 * 20
a3=table.col(2)
a3.幅= 150 * 20
a4=table.col(3)
a4.幅= 150 * 20
a5=table.col(4)
a5.幅= 150 * 20
値内の時間1の場合:
table.write(h,0,now02) # xlwtオブジェクト書き込みメソッド、パラメータは行、列、値です
table.write(h,1,float1)
table.write(h,2,float2)
table.write(h,3,float3)
table.write(h,4,float4)
Excel.save("data.xls") # xlwt オブジェクトが保存され、元の Excel が上書きされます
# まとめ
スクリプト実行コマンドは python3 で始まり、python はエラーを報告します。 スクリプトを実行する前に、スクリプトディレクトリに新しい「data.xls」を作成してファイルを保存する必要があります。
興味は最高の先生です、過去に、Pythonを学ぶとき、私はいつも配列に本を置くように感じました、しかし今私は私の心の中にアイデアを持っています、私は解決策を見つけたいので、このクモがあります。
このコードには私が本当に理解していないものがたくさんありますが、少なくとも今のところ、スクリプトは私が望むように機能します。 それでいいと思います。
完全なコード:
# コーディング = UTF-8
インポート時間
XLRDをインポートする
XLWT のインポート
インポート urllib.request
インポート再
XLRDインポートopen_workbookから
xlutils.copy からコピーをインポートする
OS のインポート
now = int(round(time.time()*1000))
now02 = time.strftime('%m-%d %H:%M',time.localtime(now/1000))
url = r'https://page あなたはクロールする必要があります' #这里我就不把查询页面贴出来了、引用符で囲まれたリンクの前に http:// または https:// を付ける必要があります それ以外の場合は、エラーが報告されます
headers ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (ヤモリのような KHTML) Chrome/55.0.2883.87 Safari/537.36'}
req = urllib.request.Request(url=url,headers=headers) #模拟浏览器
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8') #将文件用utf-8 エンコーディング
re1='.*?' # フィラーの非貪欲一致
re2='([+-]?\\d*\\.\\d{8})(?! [-+0-9\\.])' # 浮動小数点数 1
re3='.*?' # フィラーの貪欲でない一致
re4='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # 浮動小数点数2
re5='.*?' # フィラーの貪欲でない一致
re6='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # 浮動小数点数3
re7='.*?' # フィラーの貪欲でない一致
re8='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # 浮動小数点数4
rg = re.compile(re1+re2+re3+re4+re5+re6+re7+re8,re. 大文字と小文字を無視する|re. ドトール)
m = rg.search(html)
mの場合:#m内就是我需要的4串数字了。
浮動小数点数1=M.グループ(1)
浮動小数点数2=M.グループ(2)
浮動小数点数3=M.グループ(3)
浮動小数点数4=m.グループ(4)
データ = xlrd.open_workbook('データ.xls') #读取数据
page = len(data.sheets()) #获取sheet的数量
table = data.sheets()[0]#打开第一张表
nrows = table.nrows# は行の総数を取得します
ncols = table.ncols# は列の総数を取得します
h = テーブル.n行 #将行数保存下来后面写入数据的时候用
rexcel = open_workbook("data.xls") # wlrd が提供するメソッドを使用して Excel ファイルを読み込む
rows = rexcel.sheets()[0].nrows # wlrd が提供するメソッドを使用して、現在利用可能な行数を取得します。
excel = copy(rexcel) # xlutils が提供するコピー方法を使用して、xlrd オブジェクトを xlwt オブジェクトに変換する
table = excel.get_sheet(0) # xlwtオブジェクトのメソッドを使用して、操作するシートを取得します
値 = ["1"]
a1=table.col(0) #设置单元格宽度
a1.幅= 150 * 20
a2=table.col(1)
a2.幅= 150 * 20
a3=table.col(2)
a3.幅= 150 * 20
a4=table.col(3)
a4.幅= 150 * 20
a5=table.col(4)
a5.幅= 150 * 20
値内の時間1の場合:
table.write(h,0,now02) # xlwtオブジェクト書き込みメソッド、パラメータは行、列、値です
table.write(h,1,float1)
table.write(h,2,float2)
table.write(h,3,float3)
table.write(h,4,float4)
Excel.save("data.xls") # xlwt オブジェクトが保存され、元の Excel が上書きされます
タグ :
著作権に関する注意事項 :
この記事はSaltyLeoによって書かれました。誤りがある場合は、コメントでフィードバックをお願いします。この記事の転載や引用を行う場合は、CC BY-NC-SA ライセンスに従う必要があります。帰属表示、非営利利用、同一条件の共有が必要です!コメント :
続きを読む :


nginx.conf の UA 設定に従って、対応するリクエストをブロックします。

OpenAi Api を使用して、Web バージョンのアクセス制限をバイパスします。

この記事では主に、適切な VPS の選択方法と、自分に合った VPS を見つけるためのテスト方法について説明します。

この記事では、Homekit を使用して iOS Home APP に接続します。

WindowsでLinuxサーバディレクトリをアップロードする簡単な方法
 日本語
日本語 中文
中文 English
English Français
Français Deutsch
Deutsch Pу́сский язы́к
Pу́сский язы́к 한국어
한국어 Español
Español