hacer un rastreador de python
2018-10-18 · 941 · 12 min# Causa
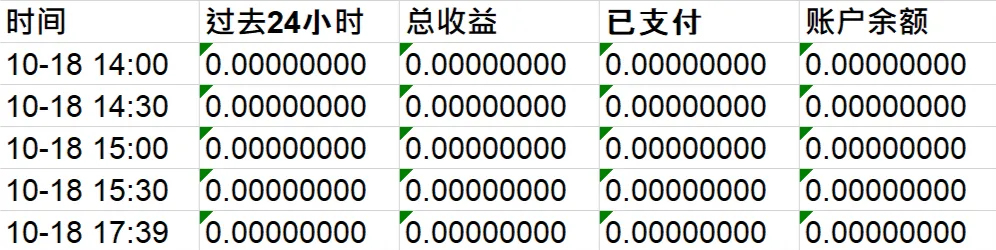
He estado minando Monero últimamente y tengo la necesidad de monitorear los datos de la billetera. Pero el grupo solo guarda datos de las últimas "24 horas", y si necesito mirar los registros anteriores, como "cuánto cavé en total este mes", no puedo hacerlo. Por lo tanto, necesito hacer un rastreador yo mismo, rastrear periódicamente los datos de la página de consulta del grupo de minería y guardarlo.
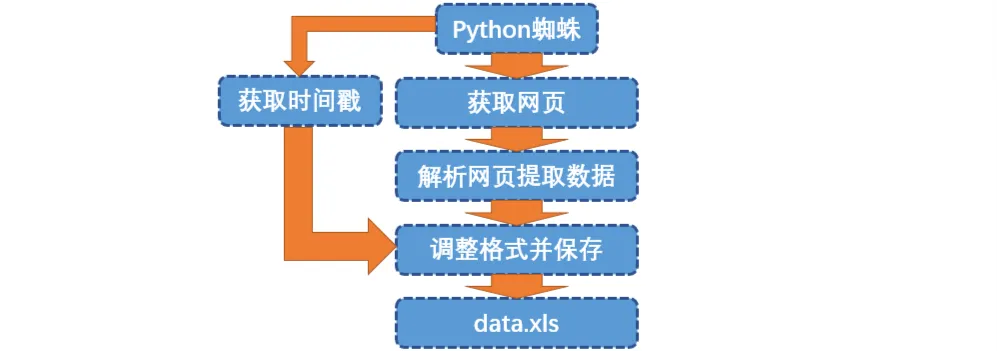
# Diagrama de flujo
# Preparativos
El sistema que estoy usando es WSL-Ubuntu 18.04, que viene con 'python3', y el proyecto necesita usar {% label success@xlrd, xlwt, xlutils%} bibliotecas, si no se instala usando el siguiente comando:
pip3 instalar xlrd xlwt xlutils
Si 'python3' o 'pip3' no están instalados, use el siguiente comando:
sudo apt-get install python3
sudo apt-get install python3-pip
# Implementación de código
Obtener tiempo
Debido a que desea ordenar los datos por tiempo al guardar Excel, primero debe obtener la marca de tiempo:
# codificación = utf-8
Tiempo de importación
now = int(round(time.time()*1000))
now02 = time.strftime('%m-%d %H:%M',time.localtime(now/1000))
Esto incluye una marca de tiempo en now02.
Rastrear la página
Los rastreadores, primero toman toda la página y luego usan herramientas normales u otras para filtrar los datos.
Importar re
importar urllib.request
url = r'https://page you need to crawl' #这里我就不把查询页面贴出来了, el enlace entre comillas debe ir precedido de un http:// o https:// De lo contrario, se informará de un error
headers ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/55.0.2883.87 Safari/537.36'} #模拟浏览器
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8') codificación #将文件用utf-8
Filtrado regular
Aquí, de acuerdo con los datos que necesita para obtener diferentes expresiones regulares, los datos que necesito son una cadena de números 0.00000000, cuatro veces seguidas con otros caracteres en el medio. (No todos los 0s, por supuesto, cualquier número de 0-9).
re1='.*?' # Coincidencia no codiciosa en el relleno
re2='([+-]?\\d*\\.\\d{8})(?! [-+0-9\\.])' # Flotador 1
re3='.*?' # Coincidencia no codiciosa en el relleno
re4='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # Flotador 2
re5='.*?' # Coincidencia no codiciosa en el relleno
re6='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # Flotador 3
re7='.*?' # Coincidencia no codiciosa en el relleno
re8='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # Flotador 4
rg = re.compile(re1+re2+re3+re4+re5+re6+re7+re8,re. IGNORECASE|re. DOTALL)
m = rg.search(html)
Si m: #m内就是我需要的4串数字了.
float1=m.group(1)
float2=m.group(2)
float3=m.group(3)
float4=m.group(4)
Leer Excel
Debido a que quiero escribir datos continuamente dentro de un Excel, necesito obtener sus datos de fila y columna para determinar dónde se escriben los datos.
Importar XLRD
desde XLRD import open_workbook
data = xlrd.open_workbook('data.xls') #读取数据
page = len(data.sheets()) #获取sheet的数量
table = data.sheets()[0]#打开第一张表
nrows = table.nrows# obtiene el número total de filas
ncols = table.ncols# obtiene el número total de columnas
h = table.nrows #将行数保存下来后面写入数据的时候用
Editar, escribir, guardar Excel
Copie el archivo de origen en la memoria, luego edite los datos en la memoria, establezca el siguiente ancho de lista y finalmente guárdelo.
rexcel = open_workbook("data.xls") # Leer un archivo de Excel utilizando el método proporcionado por wlrd
rows = rexcel.sheets()[0].nrows # Utilice el método proporcionado por wlrd para obtener el número de filas que están disponibles en la actualidad
excel = copy(rexcel) # Utilice el método copy proporcionado por xlutils para convertir objetos xlrd en objetos xlwt
table = excel.get_sheet(0) # Usar el método del objeto xlwt para manipular la hoja
valores = ["1"]
a1=table.col(0) #设置单元格宽度
a1.width=150*20
a2=tabla.col(1)
a2.width=150*20
a3=tabla.col(2)
a3.width=150*20
a4=tabla.col(3)
a4.width=150*20
a5=tabla.col(4)
a5.width=150*20
para tiempo1 en valores:
table.write(h,0,now02) # xlwt método de escritura de objetos, los parámetros son fila, columna, valor
table.write(h,1,float1)
table.write(h,2,float2)
table.write(h,3,float3)
table.write(h,4,float4)
Se guarda el objeto Excel.save("data.xls") # xlwt, sobrescribiendo el Excel original
# Resumen
El comando script run comienza con python3, y python informará de un error. Antes de ejecutar el script, debe crear un nuevo 'data.xls' en el directorio del script para guardar el archivo.
El interés es el mejor maestro, en el pasado, cuando aprendí python, siempre sentí que dejé el libro en la matriz, pero ahora tengo una idea en mi mente, quiero encontrar una solución, así que existe esta araña.
Hay muchas cosas en este código que realmente no entiendo, pero no es inutilizable, al menos por ahora, el script funciona de la manera que quiero. Creo que está bien.
Código completo:
# codificación = utf-8
Tiempo de importación
Importar XLRD
Importar XLWT
importar urllib.request
Importar re
desde XLRD import open_workbook
Desde XLUTILS.copy Importar copia
Importar sistema operativo
now = int(round(time.time()*1000))
now02 = time.strftime('%m-%d %H:%M',time.localtime(now/1000))
url = r'https://page you need to crawl' #这里我就不把查询页面贴出来了, el enlace entre comillas debe ir precedido de un http:// o https:// De lo contrario, se informará de un error
headers ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/55.0.2883.87 Safari/537.36'}
req = urllib.request.Request(url=url,headers=headers) #模拟浏览器
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8') codificación #将文件用utf-8
re1='.*?' # Coincidencia no codiciosa en el relleno
re2='([+-]?\\d*\\.\\d{8})(?! [-+0-9\\.])' # Flotador 1
re3='.*?' # Coincidencia no codiciosa en el relleno
re4='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # Flotador 2
re5='.*?' # Coincidencia no codiciosa en el relleno
re6='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # Flotador 3
re7='.*?' # Coincidencia no codiciosa en el relleno
re8='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # Flotador 4
rg = re.compile(re1+re2+re3+re4+re5+re6+re7+re8,re. IGNORECASE|re. DOTALL)
m = rg.search(html)
Si m: #m内就是我需要的4串数字了.
float1=m.group(1)
float2=m.group(2)
float3=m.group(3)
float4=m.group(4)
data = xlrd.open_workbook('data.xls') #读取数据
page = len(data.sheets()) #获取sheet的数量
table = data.sheets()[0]#打开第一张表
nrows = table.nrows# obtiene el número total de filas
ncols = table.ncols# obtiene el número total de columnas
h = table.nrows #将行数保存下来后面写入数据的时候用
rexcel = open_workbook("data.xls") # Leer un archivo de Excel utilizando el método proporcionado por wlrd
rows = rexcel.sheets()[0].nrows # Utilice el método proporcionado por wlrd para obtener el número de filas que están disponibles en la actualidad
excel = copy(rexcel) # Utilice el método copy proporcionado por xlutils para convertir objetos xlrd en objetos xlwt
table = excel.get_sheet(0) # Usar el método del objeto xlwt para manipular la hoja
valores = ["1"]
a1=table.col(0) #设置单元格宽度
a1.width=150*20
a2=tabla.col(1)
a2.width=150*20
a3=tabla.col(2)
a3.width=150*20
a4=tabla.col(3)
a4.width=150*20
a5=tabla.col(4)
a5.width=150*20
para tiempo1 en valores:
table.write(h,0,now02) # xlwt método de escritura de objetos, los parámetros son fila, columna, valor
table.write(h,1,float1)
table.write(h,2,float2)
table.write(h,3,float3)
table.write(h,4,float4)
Se guarda el objeto Excel.save("data.xls") # xlwt, sobrescribiendo el Excel original
Etiquetas :
Aviso de derechos de autor :
Este artículo está escrito por SaltyLeo. Si hay algún error en el contenido, por favor, deje un comentario. Al copiar o citar este artículo, por favor, cumpla con la licencia CC BY-NC-SA que requiere atribución, uso no comercial y compartir bajo la misma licencia.Comentario :
Leer más :


¡Este artículo le enseñará cómo pasar un año de Trello Gold gratis!
Cree un servidor Blynk privado, para que tenga "energía" ilimitada.
Para lograr este efecto, solo necesita instalar una pantalla solitaria.
También se ha actualizado la red y se ha depurado el equipo ¿Qué pasa si quiero acceder a archivos locales en la red externa?
Recientemente, estoy aprendiendo python crawler. Lo más básico es la biblioteca de solicitudes. El comando de instalación es muy simple.
Populares
 Español
Español 中文
中文 English
English Français
Français Deutsch
Deutsch 日本語
日本語 Pу́сский язы́к
Pу́сский язы́к 한국어
한국어Información del sitio
Etiquetas: 217
Vistas totales de página: 12,888,731
tiempo de carga: 69.09 ms
Ver : 3.0.1