Erstellen Sie einen Python-Crawler
2018-10-18 · 941 · 11 min# Ursache
Ich habe in letzter Zeit Monero abgebaut und muss die Wallet-Daten überwachen. Aber der Pool speichert nur Daten für die letzten "24 Stunden", und wenn ich mir vergangene Aufzeichnungen ansehen muss, z. B. "wie viel ich in diesem Monat insgesamt gegraben habe", kann ich dies nicht tun. Also muss ich selbst einen Crawler erstellen, die Daten der Mining-Pool-Abfrageseite regelmäßig crawlen und speichern.
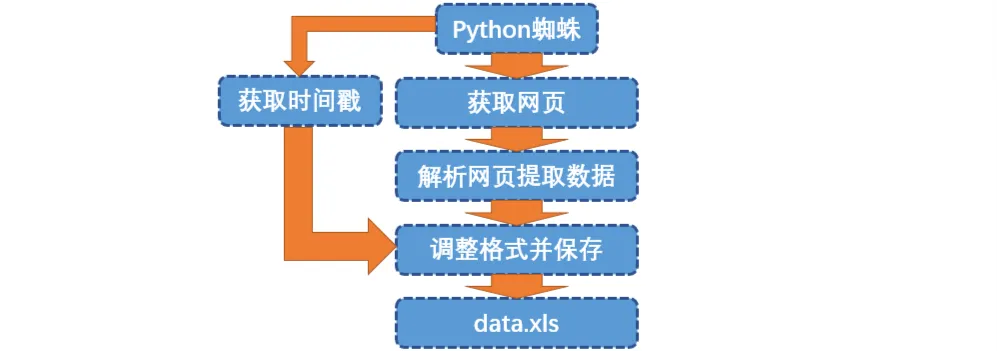
# Flussdiagramm
# Vorbereitungen
Das System, das ich verwende, ist WSL-Ubuntu 18.04, das mit 'python3' geliefert wird, und das Projekt muss {% label success@xlrd, xlwt, xlutils%} Bibliotheken verwenden, wenn es nicht mit dem folgenden Befehl installiert wird:
pip3 install xlrd xlwt xlutils
Wenn 'python3' oder 'pip3' nicht installiert ist, verwenden Sie den folgenden Befehl:
sudo apt-get python3 installieren
sudo apt-get python3-pip installieren
# Code-Implementierung
Zeit gewinnen
Da Sie die Daten beim Speichern von Excel nach Zeit sortieren möchten, müssen Sie zuerst den Zeitstempel abrufen:
# Codierung=UTF-8
Zeit importieren
now = int(round(time.time()*1000))
now02 = time.strftime('%m-%d %H:%M',time.localtime(now/1000))
Dazu gehört auch ein Zeitstempel in now02.
Crawlen Sie die Seite
Crawler greifen zuerst auf die gesamte Seite zu und verwenden dann reguläre oder andere Tools, um die Daten zu filtern.
Import Re
urllib.request importieren
url = r'https://page Sie müssen crawlen' #这里我就不把查询页面贴出来了 muss dem Link in Anführungszeichen ein http:// oder https:// vorangestellt werden. Andernfalls wird ein Fehler gemeldet
headers ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, wie Gecko) Chrome/55.0.2883.87 Safari/537.36'} #模拟浏览器
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8') #将文件用utf-8-Kodierung
Regelmäßige Filterung
Hier nach den Daten, die Sie benötigen, um verschiedene reguläre Ausdrücke auszuwählen, sind die Daten, die ich brauche, eine Zeichenfolge solcher Zahlen 0,00000000, viermal hintereinander mit anderen Zeichen dazwischen. (Natürlich nicht alle 0en, jede Zahl von 0-9.)
re1='.*?' # Nicht-gieriges Match auf Füllstoff
re2='([+-]?\\d*\\.\\d{8})(?! [-+0-9\\.])' # Schwimmer 1
re3='.*?' # Nicht-gieriges Match auf Füller
re4='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # Schwimmer 2
re5='.*?' # Nicht-gieriges Match auf Füllstoff
re6='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # Schwimmer 3
re7='.*?' # Nicht-gieriges Match auf Füllstoff
re8='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # Schwimmer 4
rg = re.compile(re1+re2+re3+re4+re5+re6+re7+re8,re. IGNORECASE|re. DOTALL)
m = rg.search(html)
Wenn m: #m内就是我需要的4串数字了.
float1=m.group(1)
float2=m.group(2)
float3=m.group(3)
float4=m.group(4)
Excel lesen
Da ich kontinuierlich Daten in einem Excel schreiben möchte, muss ich die Zeilen- und Spaltendaten abrufen, um zu bestimmen, wo die Daten geschrieben werden.
XLRD importieren
Von XLRD importieren open_workbook
data = xlrd.open_workbook('data.xls') #读取数据
page = len(data.sheets()) #获取sheet的数量
Tabelle = data.sheets()[0]#打开第一张表
nrows = table.nrows# ruft die Gesamtzahl der Zeilen ab
ncols = table.ncols# ruft die Gesamtzahl der Spalten ab
h = table.nrows #将行数保存下来后面写入数据的时候用
Bearbeiten, Schreiben, Excel speichern
Kopieren Sie die Quelldatei in den Arbeitsspeicher, bearbeiten Sie dann die Daten im Arbeitsspeicher, legen Sie die nächste Listenbreite fest und speichern Sie sie schließlich.
rexcel = open_workbook("data.xls") # Lesen Sie eine Excel-Datei mit der von wlrd bereitgestellten Methode
rows = rexcel.sheets()[0].nrows # Verwenden Sie die von wlrd bereitgestellte Methode, um die Anzahl der Zeilen zu erhalten, die heute verfügbar sind
excel = copy(rexcel) # Verwenden Sie die von xlutils bereitgestellte Kopiermethode, um xlrd-Objekte in xlwt-Objekte zu konvertieren
table = excel.get_sheet(0) # Verwenden Sie die Methode des xlwt-Objekts, um das zu bearbeitende Blatt zu erhalten
Werte = ["1"]
a1=table.col(0) #设置单元格宽度
a1.width=150*20
a2=Tabelle.col(1)
a2.width=150*20
a3=Tabelle.col(2)
a3.width=150*20
a4=Tabelle.col(3)
a4.width=150*20
a5=Tabelle.col(4)
a5.width=150*20
für time1 in Werten:
table.write(h,0,now02) # xlwt-Objektschreibmethode, die Parameter sind Zeile, Spalte, Wert
table.write(h,1,float1)
table.write(h,2,float2)
table.write(h,3,float3)
table.write(h,4,float4)
Excel.save("data.xls") # xlwt-Objekt wird gespeichert und überschreibt das ursprüngliche Excel
# Zusammenfassung
Der Skriptausführungsbefehl beginnt mit python3, und python meldet einen Fehler. Bevor Sie das Skript ausführen, müssen Sie ein neues "data.xls" im Skriptverzeichnis erstellen, um die Datei zu speichern.
Interesse ist der beste Lehrer, in der Vergangenheit, als ich Python lernte, hatte ich immer das Gefühl, das Buch in das Array zu legen, aber jetzt habe ich eine Idee im Kopf, ich möchte eine Lösung finden, also gibt es diese Spinne.
Es gibt eine Menge Dinge in diesem Code, die ich nicht wirklich verstehe, aber es ist nicht unbrauchbar, zumindest im Moment funktioniert das Skript so, wie ich es möchte. Ich denke, das ist in Ordnung.
Vollständiger Code:
# Codierung=UTF-8
Zeit importieren
XLRD importieren
XLWT importieren
urllib.request importieren
Import Re
Von XLRD importieren open_workbook
Aus xlutils.copy Kopie importieren
Importieren von Betriebssystemen
now = int(round(time.time()*1000))
now02 = time.strftime('%m-%d %H:%M',time.localtime(now/1000))
url = r'https://page Sie müssen crawlen' #这里我就不把查询页面贴出来了 muss dem Link in Anführungszeichen ein http:// oder https:// vorangestellt werden. Andernfalls wird ein Fehler gemeldet
headers ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, wie Gecko) Chrome/55.0.2883.87 Safari/537.36'}
req = urllib.request.Request(url=url,headers=headers) #模拟浏览器
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8') #将文件用utf-8-Kodierung
re1='.*?' # Nicht-gieriges Match auf Füllstoff
re2='([+-]?\\d*\\.\\d{8})(?! [-+0-9\\.])' # Schwimmer 1
re3='.*?' # Nicht-gieriges Match auf Füller
re4='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # Schwimmer 2
re5='.*?' # Nicht-gieriges Match auf Füllstoff
re6='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # Schwimmer 3
re7='.*?' # Nicht-gieriges Match auf Füllstoff
re8='([+-]?\\d*\\.\\d+)(?! [-+0-9\\.])' # Schwimmer 4
rg = re.compile(re1+re2+re3+re4+re5+re6+re7+re8,re. IGNORECASE|re. DOTALL)
m = rg.search(html)
Wenn m: #m内就是我需要的4串数字了.
float1=m.group(1)
float2=m.group(2)
float3=m.group(3)
float4=m.group(4)
data = xlrd.open_workbook('data.xls') #读取数据
page = len(data.sheets()) #获取sheet的数量
Tabelle = data.sheets()[0]#打开第一张表
nrows = table.nrows# ruft die Gesamtzahl der Zeilen ab
ncols = table.ncols# ruft die Gesamtzahl der Spalten ab
h = table.nrows #将行数保存下来后面写入数据的时候用
rexcel = open_workbook("data.xls") # Lesen Sie eine Excel-Datei mit der von wlrd bereitgestellten Methode
rows = rexcel.sheets()[0].nrows # Verwenden Sie die von wlrd bereitgestellte Methode, um die Anzahl der Zeilen zu erhalten, die heute verfügbar sind
excel = copy(rexcel) # Verwenden Sie die von xlutils bereitgestellte Kopiermethode, um xlrd-Objekte in xlwt-Objekte zu konvertieren
table = excel.get_sheet(0) # Verwenden Sie die Methode des xlwt-Objekts, um das zu bearbeitende Blatt zu erhalten
Werte = ["1"]
a1=table.col(0) #设置单元格宽度
a1.width=150*20
a2=Tabelle.col(1)
a2.width=150*20
a3=Tabelle.col(2)
a3.width=150*20
a4=Tabelle.col(3)
a4.width=150*20
a5=Tabelle.col(4)
a5.width=150*20
für time1 in Werten:
table.write(h,0,now02) # xlwt-Objektschreibmethode, die Parameter sind Zeile, Spalte, Wert
table.write(h,1,float1)
table.write(h,2,float2)
table.write(h,3,float3)
table.write(h,4,float4)
Excel.save("data.xls") # xlwt-Objekt wird gespeichert und überschreibt das ursprüngliche Excel
Tags :
Urheberrechtshinweis :
Dieser Artikel wurde von SaltyLeo verfasst. Bei Fehlern bitte eine Nachricht hinterlassen. Bei der Reproduktion oder Zitierung dieses Artikels beachten Sie bitte die CC BY-NC-SA Lizenz, die Namensnennung, nichtkommerzielle Nutzung und die gleiche Weitergabe erfordert!Kommentar :
Weiterlesen :


Eigentlich wollte ich schon früher eine ganzseitige scrollende Aufsatzseite erstellen, aber kürzlich habe ich eine 3D-Scrolling-Seite gefunden, die besser aussieht, also habe ich sie verwendet.

einige langweilige Platten

Bear ist eine sehr einfach zu bedienende und sehr gut aussehende Notizen-App
Der Hauptinhalt dieses Artikels ist das Tutorial zur grundlegenden Verwendung von ZFS, Wiederherstellung verlorener Festplatten und Speicherpool-Upgrades und -Upgrades.
Die Installation von owncloud auf dem Raspberry Pi kurz geübt
 Deutsch
Deutsch 中文
中文 English
English Français
Français 日本語
日本語 Pу́сский язы́к
Pу́сский язы́к 한국어
한국어 Español
EspañolWebsite-Informationen
Tags: 202
Gesamtseitenaufrufe: 12,888,652
Ladezeit: 11.7 ms
Ver : 3.0.1