i-book.in の自動更新 (Python クローラー)
2019-11-23 · 1074 · 1 min# 自動化スクリプト
最近 i-book.in を再設計し、自動化スクリプトを更新しましたが、特定のコードはすべてGitHubに投稿しません。
Github:電子ブッククローラー
コアデータは関係ないので、ソースコードをクロールしているだけなのでGitHubに送って、ゆっくりデータを登ることに興味があるなら自分のサーバーに利用していいし、手に入れるのが面倒なら直接【i-book.in】(https://i-book.in)でいいです。
具体的な実装方法は非常に簡単です。
1. ブックの名前を取得します。
2.名前でアルゴリアに行き、本があるかどうかを確認します。 お持ちの場合はスキップし、ない場合は解析してダウンロードします。
3. ダウンロードが完了したら、データをIPFSネットワークにアップロードし、ハッシュを解析します。
4.解析されたブックデータとipfsハッシュデータに基づいて、Algoliaが受け入れることができるJSON形式の文字に結合します。
5.jsonをAlgoliaにアップロードして、データベースに本があり、次に出くわしたときにダウンロードしないようにします。
# アンチクローラー
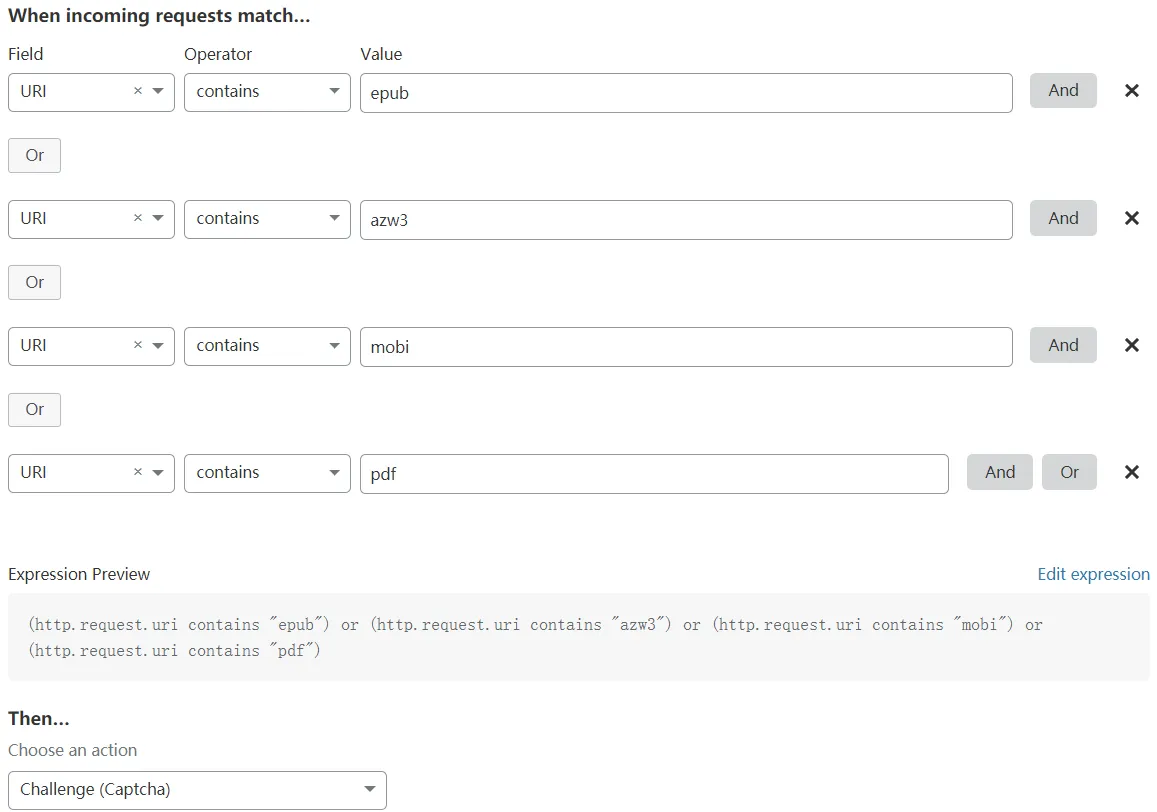
どんなサイトでもクローラーがあっても、ブログでCFシールドを設定した後、i-book.in にもCFを使用し、電子書籍のダウンロード操作にクローラー対策、つまりCFのファイアウォールルール内で設定し、電子書籍の接尾辞形式をキーワードとして設定し、これらのキーワードがキャプチャをトリガーします。 次の図は、特定の設定を示しています。
# 英語本
ウンジンさんの勉強に加えて、最近はまだ元の英語の本を這い回っていて、理解できないかもしれませんが、見れば英語もある程度学ぶことができます、最も重要なことは、登山データがとても楽しいということです~
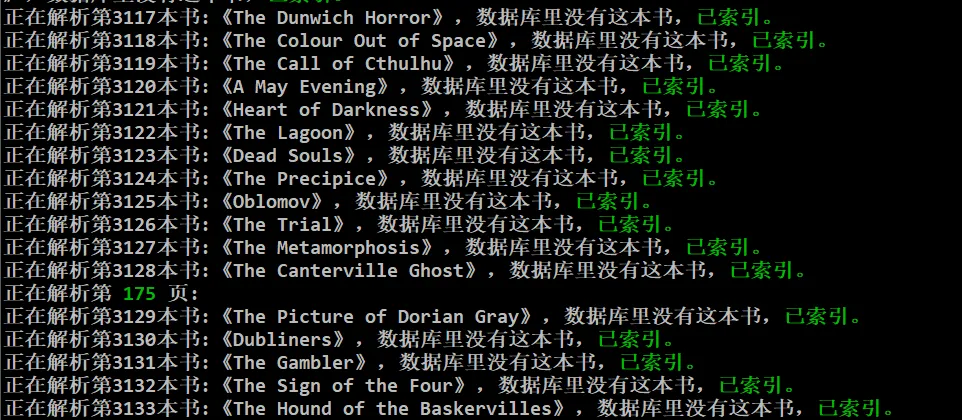
このウェブサイトはまだクロール中です、私のデバッグ上の特定のクロールコードなどは終了しました、またGitHubに置かれました、私は文句を言わなければなりません、外国人が本に名前を付ける方法はスパイシーで奇妙です、あらゆる種類の句読点、私は置き換えなければなりません、さもなければフォルダの作成は失敗し、その後のダウンロードはすべて失敗しました。
午後に合計3473冊の本をダウンロードしましたが、17冊の本のエラーがありましたが、それでも特別なシンボルの問題であるかのように、わざわざバグすることはありませんでした。
# アルゴリア口座合併
この英語の原書をすべて1つのデータベースに統合した後、データベース内のデータは1Wを超えるため、バックエンド i-book.in では、複数のAlgoliaアカウントを使用して同時に検索する必要があります。
したがって、アカウントのマージが議題になっていますが、PHPは行わないので、Python Webサービスを書き直し、インデックスを拡張するために複数のAlgoliaアカウントを組み込むか、SQLに直接書き直す予定ですが、SQLはそうではありません(ルーキーチキンは 私は正しいです。
-EOF-
タグ :
著作権に関する注意事項 :
この記事はSaltyLeoによって書かれました。誤りがある場合は、コメントでフィードバックをお願いします。この記事の転載や引用を行う場合は、CC BY-NC-SA ライセンスに従う必要があります。帰属表示、非営利利用、同一条件の共有が必要です!コメント :
続きを読む :


WAF は、ルールに従ってクローラー、SQL インジェクション、悪意のあるスキャン、および悪意のある要求をブロックし、Web サイトまたはアプリケーションのセキュリティを保護します。
優れた RSS ツール: RSSHub
ElasticSearch-py を使用するためのヒント

Flask-HTMLmin を使用して HTML コードを簡素化および圧縮する

非常にシンプルなオートタイピングのチュートリアル
 日本語
日本語 中文
中文 English
English Français
Français Deutsch
Deutsch Pу́сский язы́к
Pу́сский язы́к 한국어
한국어 Español
Español