Python爬虫实战 “恩京の书房” 全站爬取(附源码)
2019-08-19 · 1133 · 4 min最近新发现了好几个资源站,一般碰到这种我就会想办法把它全部打包到我自己的硬盘上,虽然有些不太道德,但只要你将数据公开在网络上,就等同于默认其他人可以爬取你的网站。并且如同他们没有商业化,我也没有啊。这些数据随着时间的流逝最终都会消失,与其默默的看着它消失不见,还不如让它继续发光发热。最不济我自己慢慢看总行吧。

本文主要内容为爬取恩京の书房全部电子书以及图书封面还有构建相应的json数据库,会有大量代码。还有神奇预言。
# 前言
插播一条最新消息:在撰写本文的时候,我还奇怪呢,今天小书屋的爬虫怎么没有推送我下载了那些新书(我有设置每天自动爬取最新的5本,并推送到我的手机,因为小书屋的站长每天更新只更新5本),我就去小书屋看了看,主站已经502了:
备用站也403了:
还好我提前爬过了,目前似乎只要与之相关的网站都会被狠狠打击,默默的悲哀一下吧。
而我开头写的预言就是:只要是我爬过的网站都关站了...虽然有延迟。
恩京の书房 算是我遇到过最最最干净的电子书网站了,页面简单朴素,图书质量页非常高,还有不少杂志期刊,甚至提供在线阅读。这些都不算啥,最难能可贵的是没有广告。(更正一下,在线阅读栏目有些许广告,但至少都是GoogleAds,至少不是满屏少妇那种)
排版什么的也很舒服:
恩京の书房没有使用任何的反爬虫手段,所有链接均使用了CloudFlare的CDN加速并隐藏源站,文件存储域名为shudan.io,这个域名看起来就很贵啊,打开来只有一句话:
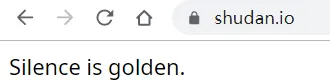
emmm...满满的嘲讽啊。站长也是个蛮有趣的人,我在互联网上找不到任何关于enjing的站长的信息,网站内也没有任何赞助链接或其它能找到的联系方式,果然是老手,匿名做得蛮到位的。希望他/她能够继续隐藏下去,希望这个站能够运营的更久吧。
# 爬虫代码
# coding: utf-8
#!/usr/bin/python3
import os
import sys
import json
import urllib.request
import re
import urllib
os.system('mkdir "/home/books"' )#新建文件夹,所有下载下来的文件将可以在这里找到。
for nums in range(1,192): #一共是1909本书,也就是191页
print(r'正在解析第%s页' %nums)
url = r'https://www.enjing.com/page/%s/' % nums
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
html=html.replace("\n", "")#剔除页面的换行符
html=html.replace("\t", "")
html=html.replace("\r", "")
link = re.findall(r'"bookmark" href="(.+?)"', html)#书每本书的链接
link1 = str(link)
json = re.findall(r'</a></p><p>(.+?)</p>', html)#每本书的简介
drlink = re.findall(r'https://www.enjing.com/(.+?)htm', link1)
drlink = str(drlink)
drlink1 = re.findall(r'\/(.+?)\.', drlink)#书的下载页面数字
for (xqlinks,inotrs,drlinks) in zip(link,json,drlink1):
#intors 作品简介
url = r'%s' % xqlinks#进入详情页面获取 书名、作者、封面
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X x.y; rv:42.0) Gecko/20100101 Firefox/42.0'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
html=html.replace("\n", "")#剔除页面的换行符
html=html.replace("\t", "")
html=html.replace("\r", "")
bookname = re.findall(r'post-preview book-describe"><h1>(.+?)</h1>', html)
bookname = str(bookname[0]) #bookname 书名
Author = re.findall(r'<p>作者:(.+?)</p>', html)
Author = str(Author[0])#Author 作者
img = re.findall(r'210" src="https://shudan.io/(.+?)" class', html)
img = str(img)#img 书的封面
img = img.replace('[','')
img = img.replace(']','')
imgtype = img.replace('/','')
imgdownload = '/usr/bin/wget --user-agent="Mozilla/5.0" -O /home/books/'+imgtype+' https://shudan.io/'+img
os.system(imgdownload) #下载图书封面
shuming = r'正在解析:%s' %bookname
print(shuming)
jsons = '{"name": "'+bookname+'","Author": "'+Author+'","intor": "'+inotrs+'","link": "your-file-server-address/home/'+bookname+'","img": "your-img-server-address/home/'+imgtype+'"},'#这里如不需要json数据可以直接注释掉这行。
url = r'https://www.enjing.com/download.php?id=%s' % drlinks#进入下载页面获取 下载链接
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
html=html.replace("\n", "")#剔除页面的换行符
html=html.replace("\t", "")
html=html.replace("\r", "")
downlink = re.findall(r'shudan.io(.+?)" target="_blank">', html)#获取不同格式的下载链接
os.system('mkdir "/home/%s"' % bookname)#新建文件夹
for xiazai in downlink:
geshi = xiazai[-4:]#获取文件格式,也就是后缀。 因为恩京的书房文件名命名的的方法太丑了,竟然直接使用拼音首字母缩写,实在看不下去。
xiazailink = 'wget --user-agent="Mozilla/5.0" -O "/home/books/'+bookname+'/'+bookname+'.'+geshi+'" https://shudan.io'+xiazai
now1= '正在下载:'+bookname+'.'+geshi
print(now1)
os.system(xiazailink) #下载图书
fileObject = open('/home/books/enjing.json', 'a')#将获取到的json保存
fileObject.write(jsons)
fileObject.write('\n')
fileObject.close()
我的运行环境是ubuntu16.04,python3.5。讲道理复制到系统就可以直接使用python运行,下载的图书和封面和json文件会在/home/books文件夹内。
具体的每个步骤的作用都有注释,生成json的部分如无需要可以直接删除。
最后:“虽然代码写的烂,但又不是不能用!!!”
# 后记
一共1909本书 enjing-full.txt ,最终下载下来的共计1871本,丢失了大约2%的数据,原因是丢失的图书标题部分包含“/”斜杠符号,导致爬虫脚本创建文件夹失败,后续的下载也就失败。为了这2%我也不打算再下载一遍。(有空我再反向遍历筛选有斜杠的下载,希望到时候enjing还没关站)
json数据爬取到了1908本,也就是丢失了一本。因为下载数据和爬取“作者、介绍、封面”是分开的,所以json的数据比较全一点。
还有一些丢失数据是由于网络问题导致wget出错,导致的下载失败。
成果:
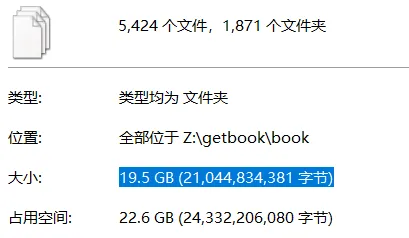
平均下载速度约0.7M/s,每本书约10.9M,每分钟下载约3.9本书,共计耗费8小时。
Tips:这类下载爬虫建议晚上运行,降低对源站造成的影响,毕竟晚上访问量少。站长也在睡觉。
-EOF-
标签 :
版权声明 :
本文由 SaltyLeo 撰写,如内容有误,请留言反馈。转载或引用本文时请遵守 CC BY-NC-SA 协议,必须署名、非商业性使用并且以相同方式共享!评论 :
阅读更多 :


如何在zsh内正常的使用通配符呢? 只需要在`~/.zshrc`内添加短短的一行命令就好
更新SSL证书的几个方法
简要的实践了在树莓派上安装owncloud的过程
GoodSync 是一个 文件同步 和 文件备份 的软件
本文将教你如何将现有的IPFS从0.4.23升级到0.5。
 中文
中文 English
English Français
Français Deutsch
Deutsch 日本語
日本語 Pу́сский язы́к
Pу́сский язы́к 한국어
한국어 Español
Español