Python crawler real combat "En Jing の Study" rastreo completo del sitio (con código fuente)
2019-08-19 · 1134 · 14 minRecientemente, he descubierto varias estaciones de recursos nuevas, y cuando me encuentre con esto, encontraré una manera de empaquetarlo todo en mi propio disco duro, aunque es un poco poco ético, pero siempre que exponga los datos en Internet, es equivalente a la forma predeterminada de que otros puedan rastrear su sitio web. Y así como no se comercializaron, yo tampoco. Estos datos eventualmente desaparecerán con el tiempo, en lugar de verlos desaparecer en silencio, es mejor dejar que continúen brillando. En el peor de los casos, me tomaré mi propio tiempo y miraré la oficina central.

El contenido principal de este artículo es rastrear todos los libros electrónicos y portadas de libros de Enkyo の Shobo, y construir la base de datos JSON correspondiente, que tendrá mucho código. Y profecías milagrosas.
# Prefacio
Inserte una nueva noticia: En el momento de escribir, todavía me preguntaba, ¿por qué el rastreador en la pequeña casa de libros de hoy no me empujó a descargar esos libros nuevos '(He configurado para rastrear automáticamente los últimos 5 libros todos los días y enviarlos a mi teléfono, porque el webmaster de la pequeña casa de libros solo actualiza 5 libros al día)', fui a la pequeña casa de libros para echar un vistazo, la estación principal ya es 502:
La estación de respaldo también es 403 arriba:
Afortunadamente, lo superé con anticipación, y parece que cualquier sitio web relacionado con él será golpeado duro, silenciosamente triste.
Y la profecía que escribí al principio fue: Mientras el sitio web que subí esté cerrado... Aunque hay un retraso.
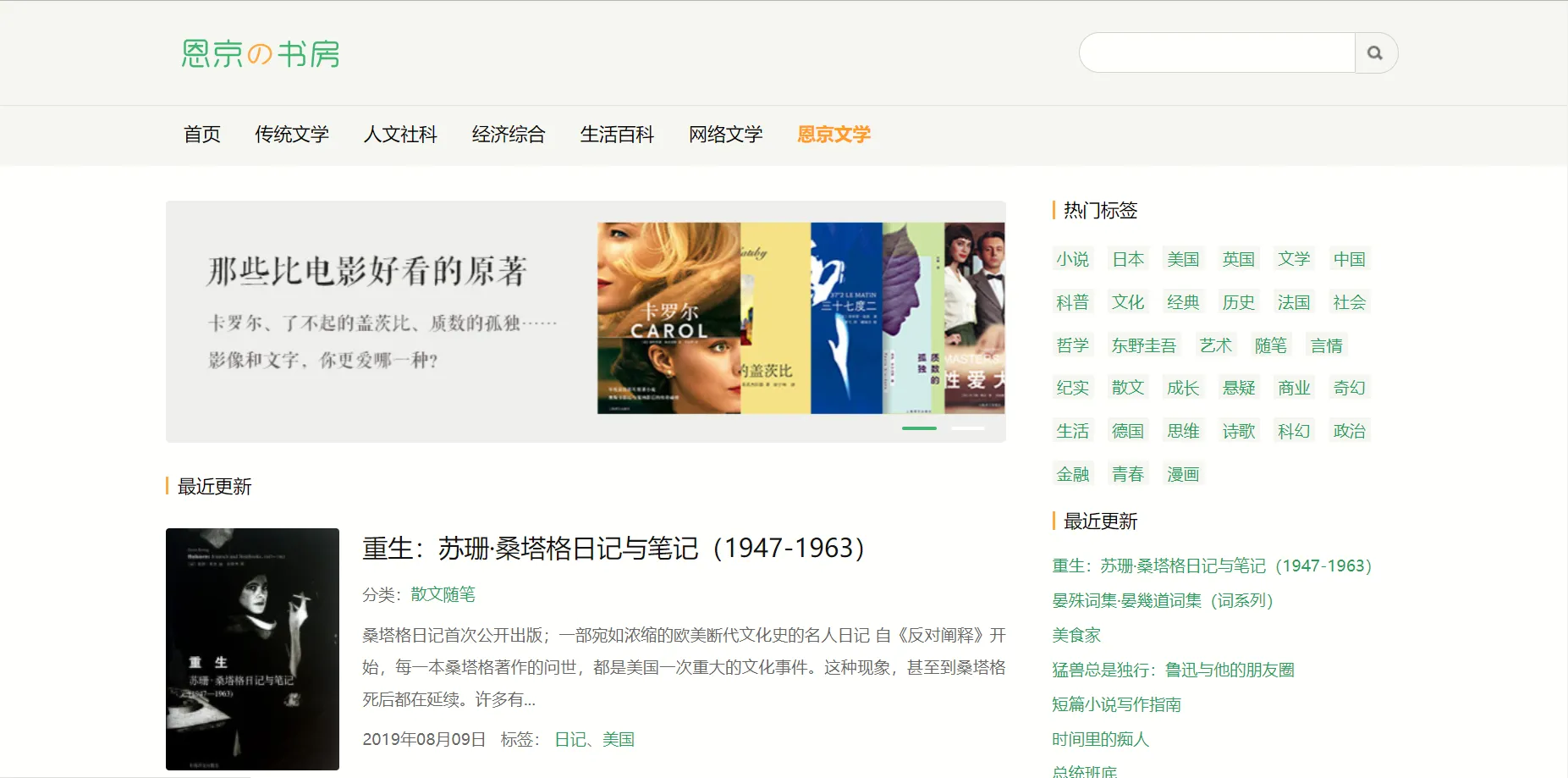
[Enkyo の書部] (https://www.enjing.com) Es el sitio de libros electrónicos más limpio que he encontrado, con páginas simples, páginas de libros de muy alta calidad y muchas revistas e incluso lectura en línea. Nada de esto es nada, lo más valioso es que no hay anuncios. (Para ser correctos, hay algunos anuncios en la sección de lectura en línea, pero al menos son todos GoogleAds, al menos no el tipo de mujer joven con pantalla completa).
La tipografía también es muy cómoda:
Enkyo の Study Room no utiliza ningún medio anti-rastreador, todos los enlaces usan la aceleración CDN de CloudFlare y ocultan el servidor de origen, el nombre de dominio de almacenamiento de archivos es 'shudan.io', este nombre de dominio parece muy caro, abra solo una oración:
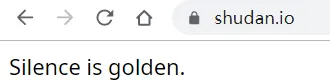
emmm... Lleno de burla. El webmaster también es una persona muy interesante, no puedo encontrar ninguna información sobre el webmaster de Enjing en Internet, y no hay enlaces de patrocinio u otra información de contacto que se pueda encontrar en el sitio web, efectivamente, soy un veterano y el anonimato está bastante en su lugar. Espero que él / ella pueda continuar escondiéndose, y espero que esta estación pueda operar por más tiempo.
# Código de rastreo
# Codificación: UTF-8
#!/usr/bin/python3
Importar sistema operativo
Importar sys
Importar JSON
importar urllib.request
Importar re
Importar urllib
os.system('mkdir "/home/books"') #新建文件夹, todos los archivos descargados estarán disponibles aquí.
Para números dentro del intervalo(1.192): #一共是1909本书 o 191 páginas
print(r'Parsing page %s' %nums)
url = r'https://www.enjing.com/page/%s/' % nums
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/55.0.2883.87 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
html=html.replace("\n", "") #剔除页面的换行符
html=html.replace("\t", "")
html=html.replace("\r", "")
link = re.findall(r'"bookmark" href="(.+?)"', html)#书每本书的链接
link1 = str(enlace)
json = re.findall(r'(.</a></p><p>+?</p>)', html)#每本书的简介
drlink = re.findall(r'https://www.enjing.com/(.+?) htm', enlace1)
drlink = str(drlink)
drlink1 = re.findall(r'\/(.+?) \.', drlink) #书的下载页面数字
Para (xqlinks,inotrs,drlinks) en zip(link,json,drlink1):
#intors Introducción al trabajo
url = r'%s' % xqlinks# Vaya a la página de detalles para obtener el título, autor, portada
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X x.y; rv:42.0) Gecko/20100101 Firefox/42.0'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
html=html.replace("\n", "") #剔除页面的换行符
html=html.replace("\t", "")
html=html.replace("\r", "")
bookname = re.findall(r'post-preview book-describe"><h1>(.+?</h1>)', html)
bookname = str(bookname[0]) #bookname el título del libro
Autor = re.findall(<p>r'author:(.+?)'</p>, html)
Autor = str(Autor[0])#Author autor
img = re.findall(r'210" src="https://shudan.io/(.+?)" class', html)
img = str(img)#img La portada del libro
img = img.replace('[','')
img = img.replace(']','')
imgtype = img.replace('/','')
imgdownload = '/usr/bin/wget --user-agent="Mozilla/5.0" -O /home/books/'+imgtype+' https://shudan.io/'+img
os.system(imgdownload) #下载图书封面
shuming = r' parsing: %s' %bookname
imprimir(shuming)
jsons = '{"name": "'+bookname+'","Author": "'+Author+'","intor": "'+inotrs+'","link": "your-file-server-address/home/'+bookname+'","img": "your-img-server-address/home/'+ imgtype+'"},'#这里如不需要json数据可以直接注释掉这行.
url = r'https://www.enjing.com/download.php?id=%s' % drlinks# Vaya a la página de descarga para obtener el enlace de descarga
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/55.0.2883.87 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
html=html.replace("\n", "") #剔除页面的换行符
html=html.replace("\t", "")
html=html.replace("\r", "")
downlink = re.findall(r'shudan.io(.+?)" target="_blank">', html)#获取不同格式的下载链接
os.system('mkdir "/home/%s"' % bookname)#新建文件夹
Para Xiazai en enlace descendente:
geshi = xiazai[-4:]#获取文件格式, que es el sufijo. Debido a que el método para nombrar el nombre del archivo del estudio de Enjing es tan feo, incluso usa directamente el acrónimo pinyin, que es realmente insoportable.
xiazailink = 'wget --user-agent="Mozilla/5.0" -O "/home/books/'+bookname+'/'+bookname+'.' +geshi+'" https://shudan.io'+xiazai
now1= 'Descargando:'+bookname+'.' +geshi
imprimir(ahora1)
os.system(xiazailink) #下载图书
fileObject = open('/home/books/enjing.json', 'a')#将获取到的json保存
fileObject.write(jsons)
fileObject.write('\n')
fileObject.close()
Mi entorno de ejecución es ubuntu 16.04, python 3.5. Reason se puede copiar al sistema y ejecutar directamente en Python, y los libros y portadas descargados y los archivos JSON estarán en la carpeta '/ home / books'.
Se comenta el rol específico de cada paso y la parte que genera JSON se puede eliminar directamente si es necesario.
Finalmente: * "Aunque el código está mal escrito, no es inutilizable!!! "*
# Posdata
Un total de 1909 libros [enjing-full.txt] (https://onedrive.live.com/embed?resid=5DD85E8F07B732DC!132388&filename=enjing-full.txt&authkey=!AB743xY84iFsrWQ), un total de 1871 libros fueron finalmente descargados, y alrededor del 2% de los datos se perdieron. La razón es que la parte del título del libro que falta contiene un símbolo de barra diagonal "/", lo que hace que el script del rastreador no pueda crear una carpeta y las descargas posteriores fallen. Por el bien de este 2%, tampoco planeo descargarlo nuevamente. (Cuando tenga tiempo, invertiré el recorrido y filtraré las descargas con barras, esperando que para entonces Enjing no cierre el sitio).
Los datos JSON se rastrearon a 1908 copias, es decir, perdieron una. Debido a que los datos de descarga y el rastreo "autor, introducción, portada" están separados, los datos JSON están un poco más completos.
Algunos de los datos perdidos se deben a problemas de red que causan errores wget, lo que resulta en fallas de descarga.
Logro:
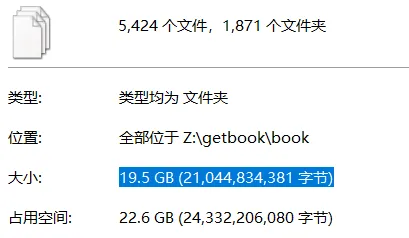
* La velocidad de descarga promedio es de aproximadamente 0.7M / s, cada libro es de aproximadamente 10.9M, y la descarga de aproximadamente 3.9 libros por minuto toma un total de 8 horas. *
Consejos: Se recomienda que este tipo de rastreador de descargas se ejecute por la noche para reducir el impacto en el servidor de origen, después de todo, el número de visitas por la noche es pequeño. El webmaster también está durmiendo.
-EF-
Etiquetas :
Aviso de derechos de autor :
Este artículo está escrito por SaltyLeo. Si hay algún error en el contenido, por favor, deje un comentario. Al copiar o citar este artículo, por favor, cumpla con la licencia CC BY-NC-SA que requiere atribución, uso no comercial y compartir bajo la misma licencia.Comentario :
Leer más :


Solucione el error que falló la prueba de idoneidad de dispositivos móviles de Google

Configurar manualmente el temporizador y reiniciar V2ray.
Pero debería ser que la configuración de Dash to dock se ha hecho cargo de la configuración de dock del sistema. Cuando enciende Dash to dock, causará acoplamientos dobles.

El contenido principal de este artículo es cómo usar Publicar en IPFS para publicar documentos en la red IPFS y permitir que otros nodos ayuden en el almacenamiento permanente.
¡Agregue colecciones de iconos de Font Awesome a su sitio de WordPress!
Tabla de contenidos
Populares
 Español
Español 中文
中文 English
English Français
Français Deutsch
Deutsch 日本語
日本語 Pу́сский язы́к
Pу́сский язы́к 한국어
한국어Información del sitio
Etiquetas: 219
Vistas totales de página: 12,891,370
tiempo de carga: 11.98 ms
Ver : 3.0.1