Поисковый робот Python, реальный бой "En Jing の Study", полное сканирование сайта (с исходным кодом)
18 August 2019 г. · 1142 · 14 minНедавно я обнаружил несколько новых ресурсных станций, и когда я столкнусь с этим, я найду способ упаковать все это на свой собственный жесткий диск, хотя это немного неэтично, но пока вы раскрываете данные в Интернете, это эквивалентно тому, что другие могут сканировать ваш сайт по умолчанию. И точно так же, как они не были коммерциализированы, и я тоже. Эти данные в конечном итоге со временем исчезнут, вместо того, чтобы молча наблюдать, как они исчезают, лучше позволить им продолжать сиять. В худшем случае я не тороплюсь и загляну в головной офис.

Основное содержание этой статьи состоит в том, чтобы просканировать все электронные книги и обложки книг Enkyo の Shabo и создать соответствующую базу данных JSON, в которой будет много кода. И чудесные пророчества.
# Предисловие
Вставьте новую новость: На момент написания я все еще задавался вопросом, почему сканер в маленьком книжном доме сегодня не подтолкнул меня к загрузке этих новых книг (я настроил автоматическое сканирование последних 5 книг каждый день и отправляю их на свой телефон, потому что веб-мастер небольшого книжного дома обновляет только 5 книг в день)», я пошел в маленький книжный дом, чтобы посмотреть, главная станция уже 502:
Резервная станция также 403 вверх:
К счастью, я пролез через него заранее, и кажется, что любой сайт, связанный с ним, сильно ударит, молча грустный.
И пророчество, которое я написал в начале, было: Пока сайт, на который я поднялся, закрыт... Хотя задержка есть.
[Энкё の書部] (https://www.enjing.com) Это самый чистый сайт электронных книг, с которым я когда-либо сталкивался, с простыми страницами, страницами очень высокого качества книги, множеством журналов и даже онлайн-чтением. Ничего из этого нет, самое ценное, что нет рекламы. (Если быть точным, в разделе онлайн-чтения есть некоторые объявления, но, по крайней мере, это все GoogleAds, по крайней мере, не из тех молодых женщин с полноэкранным экраном)
Типографика также очень удобна:
Enkyo の Study Room не использует никаких средств защиты от краулеров, все ссылки используют ускорение CDN CloudFlare и скрывают исходный сервер, доменное имя хранилища файлов - «shudan.io», это доменное имя выглядит очень дорого, откройте только одно предложение:
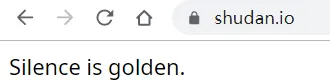
Эммм... Полно издевательств. Веб-мастер тоже очень интересный человек, я не могу найти никакой информации о веб-мастере Enjing в Интернете, и на сайте нет спонсорских ссылок или другой контактной информации, которую можно найти, конечно, я ветеран, и анонимность вполне на месте. Я надеюсь, что он/она сможет продолжать прятаться, и я надеюсь, что эта станция сможет работать дольше.
# Код краулера
# Кодировка: UTF-8
#!/usr/bin/python3
Импорт ОС
Импорт SYS
Импорт JSON
Импорт urllib.request
Импорт RE
Импорт urllib
os.system('mkdir "/home/books"') #新建文件夹, все скачанные файлы будут доступны здесь.
для чисел в диапазоне (1,192): #一共是1909本书 или 191 страница
print(r'Parsing page %s' %nums)
url = r'https://www.enjing.com/page/%s/' % nums
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, как Gecko) Chrome/55.0.2883.87 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
html=html.replace("\n", "") #剔除页面的换行符
html=html.replace("\t", "")
html=html.replace("\r", "")
link = re.findall(r'"bookmark" href="(.+?)"', html)#书每本书的链接
link1 = str(ссылка)
json = re.findall(r'(.</a></p><p>+?</p>)', html)#每本书的简介
drlink = re.findall(r'https://www.enjing.com/(.+?) htm', ссылка1)
drlink = str(drlink)
drlink1 = re.findall(r'\/(.+?) \.', drlink) #书的下载页面数字
Для (xqlinks,inotrs,drlinks) в zip(link,json,drlink1):
#intors Введение в работу
url = r'%s' % xqlinks# Перейдите на страницу сведений, чтобы получить название, автора, обложку
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X x.y; rv:42.0) Gecko/20100101 Firefox/42.0'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
html=html.replace("\n", "") #剔除页面的换行符
html=html.replace("\t", "")
html=html.replace("\r", "")
bookname = re.findall(r'post-preview book-describe"><h1>(.+?</h1>)', html)
bookname = str(bookname[0]) #bookname название книги
Author = re.findall(<p>r'author:(.+?)'</p>, html)
Автор = str(Автор[0])#Author автор
img = re.findall(r'210" src="https://shudan.io/(.+?)" class', html)
img = str(img)#img Обложка книги
img = img.replace('[','')
img = img.replace(']','')
imgtype = img.replace('/','')
imgdownload = '/usr/bin/wget --user-agent="Mozilla/5.0" -O /home/books/'+imgtype+' https://shudan.io/'+img
os.system(imgdownload) #下载图书封面
shuming = r' parsing: %s' %bookname
Печать (шуминг)
jsons = '{"name": "''+bookname+'","Author": "'+Author+'","intor": "'+inotrs+'","link": "your-file-server-address/home/'+bookname+'","img": "your-img-server-address/home/'+ imgtype+'"},'#这里如不需要json数据可以直接注释掉这行.
url = r'https://www.enjing.com/download.php?id=%s' % drlinks# Перейдите на страницу загрузки, чтобы получить ссылку для скачивания
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, как Gecko) Chrome/55.0.2883.87 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
html=html.replace("\n", "") #剔除页面的换行符
html=html.replace("\t", "")
html=html.replace("\r", "")
downlink = re.findall(r'shudan.io(.+?)" target="_blank">', html)#获取不同格式的下载链接
os.system('mkdir "/home/%s"' % bookname)#新建文件夹
Для Xiazai в нисходящем канале:
geshi = xiazai[-4:]#获取文件格式, который является суффиксом. Поскольку метод именования имени файла исследования Энджина настолько уродлив, он даже напрямую использует аббревиатуру пиньинь, что действительно невыносимо.
xiazailink = 'wget --user-agent="Mozilla/5.0" -O "/home/books/'+bookname+'/'+bookname+'.' +geshi+'" https://shudan.io'+xiazai
now1= 'Загрузка:'+bookname+'.' +геши
печать(сейчас1)
os.system(xiazailink) #下载图书
fileObject = open('/home/books/enjing.json', 'a')#将获取到的json保存
fileObject.write(jsons)
fileObject.write('\n')
fileObject.close()
Моя среда выполнения - ubuntu 16.04, python 3.5. Reason можно скопировать в систему и запустить непосредственно в Python, а загруженные книги, обложки и файлы JSON будут находиться в папке «/home/books».
Конкретная роль каждого шага комментируется, и часть, которая генерирует JSON, может быть удалена напрямую, если это необходимо.
Наконец: * «Хотя код плохо написан, он не является непригодным для использования!!! "*
# Постскриптум
В общей сложности было загружено 1909 книг [enjing-full.txt] (https://onedrive.live.com/embed?resid=5DD85E8F07B732DC!132388&filename=enjing-full.txt&authkey=!AB743xY84iFsrWQ), в общей сложности 1871 книга, и около 2% данных было потеряно. Причина в том, что отсутствующая часть названия книги содержит символ косой черты «/», что приводит к тому, что сценарий обходчика не может создать папку и последующие загрузки завершаются сбоем. Ради этих 2% я тоже не планирую скачивать его снова. (Когда у меня будет время, я буду переворачивать и фильтровать загрузки с косой чертой, надеясь, что к тому времени Enjing не закроет сайт)»
Данные JSON доползли до 1908 копий, то есть потеряли одну. Поскольку данные загрузки и сканирование «автор, введение, обложка» разделены, данные JSON немного полнее.
Некоторые из потерянных данных связаны с сетевыми проблемами, вызывающими ошибки wget, что приводит к сбоям загрузки.
Достижение:
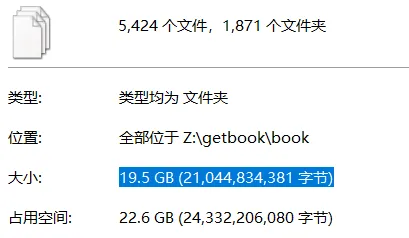
* Средняя скорость загрузки составляет около 0,7 млн / с, каждая книга - около 10,9 млн, а загрузка около 3,9 книг в минуту занимает в общей сложности 8 часов. *
Советы: Этот тип поискового робота рекомендуется запускать ночью, чтобы уменьшить влияние на исходный сервер, в конце концов, количество посещений ночью невелико. Вебмастер тоже спит.
-ЭОФ-
Теги :
Уведомление об авторском праве :
Эта статья написана SaltyLeo. Если в содержимом есть неточности, пожалуйста, оставьте комментарий. При цитировании или публикации этой статьи, пожалуйста, придерживайтесь условий лицензии CC BY-NC-SA: указание авторства, некоммерческое использование и совместное распространение в том же виде!Комментарий :
Читать далее :


Необъяснимые мысли в моей голове, почему это происходит? Почему это не прямая линия с четким черным и белым, а все более размытая?

В этой статье будет представлен подключаемый модуль nginx nginxhttprealip_module, который можно использовать для получения IP-адреса посетителя в простой ситуации с многоуровневым прокси.
Конфигурация очень удобная, отладка очень простая, а позиционирование очень понятное. Это комплексная платформа PaaS, которая может получить доступ к сотням API-интерфейсов сетевых приложений и может значительно расширяться!

Включите удаленный рабочий стол для облегчения разработки и отладки
Недавно тема моего блога была обновлена, и WordPress предложил мне обновиться, но было предложено, что обновление не может быть завершено из-за недостаточных разрешений.
Содержание
Популярные теги
Другие языки
 Pу́сский язы́к
Pу́сский язы́к 中文
中文 English
English Français
Français Deutsch
Deutsch 日本語
日本語 한국어
한국어 Español
EspañolИнформация о сайте
Теги: 238
Просмотры страниц: 12,931,949
загрузка занимает время: 16.6 ms
Ver : 3.0.1