Python-Crawler tatsächlicher Kampf "En Jing の Study" vollständiges Site-Crawling (mit Quellcode)
18. August 2019 · 1135 · 13 minIn letzter Zeit habe ich mehrere neue Ressourcenstationen entdeckt, und wenn ich darauf stoße, werde ich einen Weg finden, alles auf meine eigene Festplatte zu packen, obwohl es ein wenig unethisch ist, aber solange Sie die Daten im Internet offenlegen, ist es gleichbedeutend mit der Standardeinstellung, dass andere Ihre Website crawlen können. Und so wie sie nicht kommerzialisiert wurden, tat ich es auch nicht. Diese Daten werden schließlich im Laufe der Zeit verschwinden, anstatt stillschweigend zuzusehen, wie sie verschwinden, ist es besser, sie weiter leuchten zu lassen. Im schlimmsten Fall nehme ich mir Zeit und schaue mir die Zentrale an.

Der Hauptinhalt dieses Artikels besteht darin, alle E-Books und Buchcover von Enkyo の Shobo zu crawlen und die entsprechende JSON-Datenbank zu erstellen, die viel Code enthält. Und wundersame Prophezeiungen.
# Vorwort
Fügen Sie eine neue Nachricht ein: Zum Zeitpunkt des Schreibens habe ich mich immer noch gefragt, warum der Crawler im kleinen Bücherhaus mich heute nicht dazu gedrängt hat, diese neuen Bücher herunterzuladen (ich habe mich so eingerichtet, dass sie jeden Tag automatisch die neuesten 5 Bücher crawlen und auf mein Handy schieben, weil der Webmaster des kleinen Buchhauses nur 5 Bücher pro Tag aktualisiert), ich ging zum kleinen Bücherhaus, um einen Blick darauf zu werfen, der Hauptbahnhof ist bereits 502:
Die Backup-Station ist ebenfalls 403 hoch:
Glücklicherweise bin ich im Voraus durchgeklettert, und es scheint, dass jede Website, die damit zu tun hat, hart und stillschweigend traurig getroffen wird.
Und die Prophezeiung, die ich am Anfang geschrieben habe, war: Solange die Website, auf die ich geklettert bin, geschlossen ist... Obwohl es eine Verzögerung gibt.
[Enkyo の書部] (https://www.enjing.com) Es ist die sauberste E-Book-Site, die mir je begegnet ist, mit einfachen Seiten, Seiten in sehr hoher Buchqualität und vielen Zeitschriften und sogar Online-Lektüre. Nichts davon ist nichts, das Wertvollste ist, dass es keine Werbung gibt. (Um korrekt zu sein, gibt es einige Anzeigen im Online-Lesebereich, aber zumindest ist es alles GoogleAds, zumindest nicht die Art von junger Frau mit einem Vollbildmodus)
Typografie ist auch sehr komfortabel:
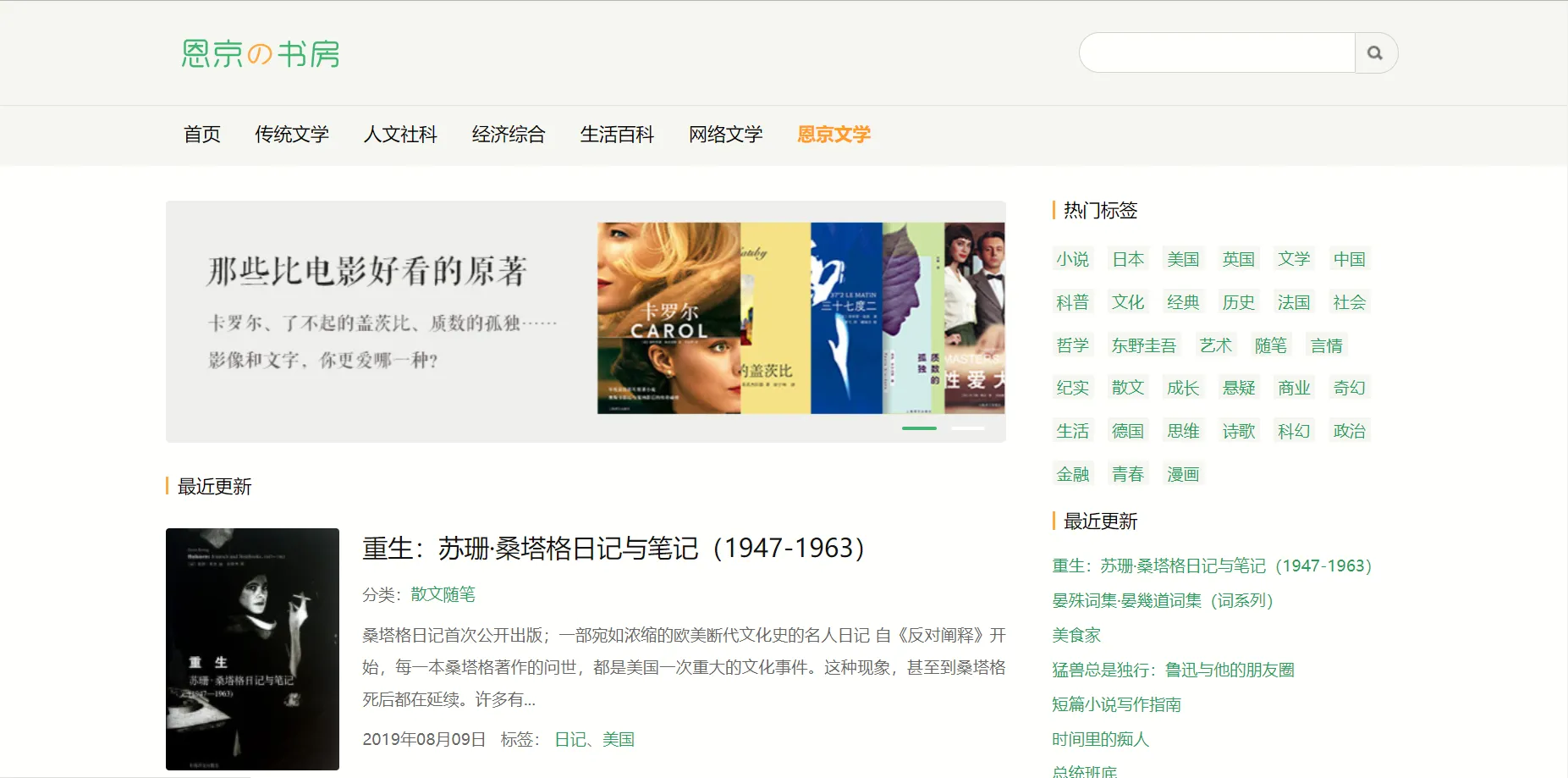
Enkyo の Study Room verwendet keine Anti-Crawler-Mittel, alle Links verwenden die CDN-Beschleunigung von CloudFlare und verbergen den Ursprungsserver, der Domainname des Dateispeichers lautet "shudan.io", dieser Domainname sieht sehr teuer aus, öffnen Sie nur einen Satz:
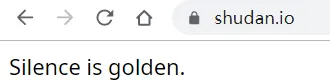
emmm... Voller Spott. Der Webmaster ist auch eine sehr interessante Person, ich kann keine Informationen über den Webmaster von Enjing im Internet finden, und es gibt keine Sponsoring-Links oder andere Kontaktinformationen, die auf der Website zu finden sind, sicher genug, ich bin ein Veteran, und die Anonymität ist ziemlich vorhanden. Ich hoffe, er/sie kann sich weiterhin verstecken, und ich hoffe, dass diese Station länger arbeiten kann.
# Crawler-Code
# Codierung: UTF-8
#!/usr/bin/python3
Importieren von Betriebssystemen
sys importieren
JSON importieren
urllib.request importieren
Import Re
urllib importieren
os.system('mkdir "/home/books"') #新建文件夹, alle heruntergeladenen Dateien sind hier verfügbar.
für Nummern im Bereich (1.192): #一共是1909本书 oder 191 Seiten
print(r'Parsing page %s' %nums)
url = r'https://www.enjing.com/page/%s/' % nums
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, wie Gecko) Chrome/55.0.2883.87 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
html=html.replace("\n", "") #剔除页面的换行符
html=html.replace("\t", "")
html=html.replace("\r", "")
link = re.findall(r'"bookmark" href="(.+?)"', html)#书每本书的链接
link1 = str(link)
json = re.findall(r'(.</a></p><p>+?</p>)', html)#每本书的简介
drlink = re.findall(r'https://www.enjing.com/(.+?) htm', link1)
drlink = str(drlink)
drlink1 = re.findall(r'\/(.+?) \.', drlink) #书的下载页面数字
für (xqlinks,inotrs,drlinks) in zip(link,json,drlink1):
#intors Einführung in die Arbeit
url = r'%s' % xqlinks# Gehen Sie zur Detailseite, um den Titel, den Autor und das Cover zu erhalten
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X x.y; rv:42.0) Gecko/20100101 Firefox/42.0'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
html=html.replace("\n", "") #剔除页面的换行符
html=html.replace("\t", "")
html=html.replace("\r", "")
bookname = re.findall(r'post-preview book-describe"><h1>(.+?</h1>)', html)
bookname = str(bookname[0]) #bookname den Titel des Buches
Autor = re.findall(<p>r'author:(.+?)'</p>, html)
Autor = str(Autor[0])#Author Autor
img = re.findall(r'210" src="https://shudan.io/(.+?)" class', html)
img = str(img)#img Das Cover des Buches
img = img.replace('[','')
img = img.replace(']','')
imgtype = img.replace('/','')
imgdownload = '/usr/bin/wget --user-agent="Mozilla/5.0" -O /home/books/'+imgtype+' https://shudan.io/'+img
os.system(imgdownload) #下载图书封面
shuming = r' parsing: %s' %bookname
drucken (shuming)
jsons = '{"name": "'+Buchname+'","Autor": "'+Autor+'","intor": "'+inotrs+'","link": "your-file-server-address/home/'+bookname+'",""img": "your-img-server-address/home/'+ imgtype+'"},'#这里如不需要json数据可以直接注释掉这行.
url = r'https://www.enjing.com/download.php?id=%s' % drlinks# Gehen Sie zur Download-Seite, um den Download-Link zu erhalten
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, wie Gecko) Chrome/55.0.2883.87 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
html=html.replace("\n", "") #剔除页面的换行符
html=html.replace("\t", "")
html=html.replace("\r", "")
downlink = re.findall(r'shudan.io(.+?)" target="_blank">', html)#获取不同格式的下载链接
os.system('mkdir "/home/%s"' % bookname)#新建文件夹
Für Xiazai im Downlink:
geshi = xiazai[-4:]#获取文件格式, was das Suffix ist. Weil die Methode zur Benennung des Dateinamens von Enjings Studie so hässlich ist, verwendet er sogar direkt das Akronym Pinyin, was wirklich unerträglich ist.
xiazailink = 'wget --user-agent="Mozilla/5.0" -O "/home/books/'+bookname+'/'+bookname+'.' +geshi+'" https://shudan.io'+xiazai
now1= 'Herunterladen:'+Buchname+'.' +geshi
print(now1)
os.system(xiazailink) #下载图书
fileObject = open('/home/books/enjing.json', 'a')#将获取到的json保存
fileObject.write(jsons)
fileObject.write('\n')
fileObject.close()
Meine Laufzeitumgebung ist Ubuntu 16.04, Python 3.5. Reason kann auf das System kopiert und direkt in Python ausgeführt werden, und die heruntergeladenen Bücher und Cover sowie JSON-Dateien befinden sich im Ordner '/home/books'.
Die spezifische Rolle jedes Schritts wird kommentiert, und der Teil, der JSON generiert, kann bei Bedarf direkt gelöscht werden.
Schließlich: * "Obwohl der Code schlecht geschrieben ist, ist er nicht unbrauchbar!!! "*
# Nachtrag
Insgesamt 1909 Bücher [enjing-full.txt] (https://onedrive.live.com/embed?resid=5DD85E8F07B732DC!132388&filename=enjing-full.txt&authkey=!AB743xY84iFsrWQ), insgesamt 1871 Bücher wurden schließlich heruntergeladen, und etwa 2% der Daten gingen verloren. Der Grund dafür ist, dass der fehlende Buchtitelteil einen "/"-Schrägstrich enthält, der dazu führt, dass das Crawler-Skript keinen Ordner erstellt und nachfolgende Downloads fehlschlagen. Für diese 2% habe ich auch nicht vor, es erneut herunterzuladen. (Wenn ich Zeit habe, werde ich das Traversieren umkehren und Downloads mit Schrägstrichen filtern, in der Hoffnung, dass Enjing bis dahin die Site nicht schließen wird.)
Die JSON-Daten wurden auf 1908 Kopien gecrawlt, dh eine verloren. Da die Download-Daten und das Crawling "Autor, Einleitung, Cover" getrennt sind, sind die JSON-Daten etwas voller.
Einige der verlorenen Daten sind auf Netzwerkprobleme zurückzuführen, die wget-Fehler verursachen, die zu Download-Fehlern führen.
Leistung:
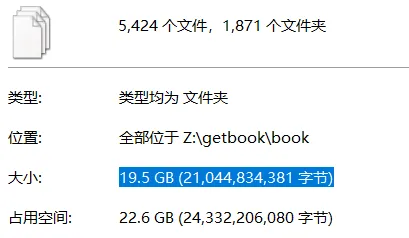
*Die durchschnittliche Download-Geschwindigkeit beträgt etwa 0,7 Mio. / s, jedes Buch etwa 10,9 Mio. und der Download von etwa 3,9 Büchern pro Minute dauert insgesamt 8 Stunden. *
Tipps: Es wird empfohlen, diese Art von Download-Crawler nachts auszuführen, um die Auswirkungen auf den Ursprungsserver zu verringern, schließlich ist die Anzahl der Besuche in der Nacht gering. Der Webmaster schläft ebenfalls.
-EOF-
Tags :
Urheberrechtshinweis :
Dieser Artikel wurde von SaltyLeo verfasst. Bei Fehlern bitte eine Nachricht hinterlassen. Bei der Reproduktion oder Zitierung dieses Artikels beachten Sie bitte die CC BY-NC-SA Lizenz, die Namensnennung, nichtkommerzielle Nutzung und die gleiche Weitergabe erfordert!Kommentar :
Weiterlesen :


Verwenden Sie bottle_mobility, um Gerätetypen schnell zu identifizieren

Beenden Sie den Gunicorn-Prozess manuell und starten Sie den Prozess neu

Bauen Sie einen privaten Blynk-Server auf, damit Sie unbegrenzte „Energie“ haben.

Windows-Remotedesktop-Tipps
Dies ist der erste Artikel in der Serie zur Nutzung alter Maschinen, und es ist auch ein sehr wichtiger Artikel, da sich der Server im internen Netzwerk befindet, wird dieser Artikel die interne FRP-Netzwerkdurchdringung dafür konfigurieren
Inhaltsverzeichnis
 Deutsch
Deutsch 中文
中文 English
English Français
Français 日本語
日本語 Pу́сский язы́к
Pу́сский язы́к 한국어
한국어 Español
EspañolWebsite-Informationen
Tags: 202
Gesamtseitenaufrufe: 12,893,083
Ladezeit: 75.85 ms
Ver : 3.0.1