Python Crawler Advanced - bahnbrechender Anti-Crawler
04. May 2019 · 1002 · 24 minIch bin ein Sammler und möchte gute Ressourcen sammeln, aber es ist zu zeitaufwändig und mühsam, sie einzeln herunterzuladen, also habe ich die vorherige [API und Crawler] (http://tstrs.me/1447.html), aber jetzt entfernen Webmaster nach und nach Urheberrechtsbeschränkungen, also parse ich nicht nur Dateilinks, ich möchte sie auf meiner eigenen Festplatte speichern.
Später habe ich eine Cloud-Festplatte [TSTR_Cloud] (https://cloud.tstrs.me) zum Teilen erstellt. Ich gehe oft am Fluss entlang, wie kann ich meine Schuhe nicht nass machen, meine Cloud-Festplatte wird auch von Crawlern gecrawlt, ich muss sie privatisieren, ich muss ein Passwort verwenden, um darauf zuzugreifen.
Aber ich kratze immer noch E-Books von verschiedenen Websites und speichere sie, die derzeit 52G sind, etwa 5300 Exemplare.

Der Hauptinhalt dieses Artikels sind Anti-Crawler-Strategien und Anti-Crawler-Tipps.
# Anti-Crawler
Die aktuellen Anti-Crawler-Maßnahmen reichen von leicht bis schwierig:
IP
Der Datenverkehr einer IP-Adresse steigt an, und die IP wird gezielt blockiert.
UserAgent
Identifizierung von nicht-menschlichen Useragents, die blockiert sind, z.B. JavaClient 1.6
Frequenz
Je nach Zugriffsfrequenz einer bestimmten IP wird der Zugriff zu häufig in der Einheit Zeit gesperrt.
Captcha
Ein Captcha ist erforderlich, um Daten abzurufen.
JS-Verschlüsselung
JS-verschlüsseln Sie die Daten.
Keks
Sie müssen bei Ihrem Konto angemeldet sein, um crawlen zu können.
All dies basiert auf den Erfahrungen anderer großer Jungs, und ich bin bisher nur den ersten drei begegnet.
# Anti-Anti-Crawler
Proxy-IP
Verwenden Sie Proxy-IPs, um die Wahrscheinlichkeit zu verringern, dass Blöcke basierend auf IP identifiziert werden.
Simulieren Sie den Useragent
Die Verwendung eines Useragents wie "Mozilla/5.0" verringert die Wahrscheinlichkeit einer Ablehnung einer Website.
Geplanter Schlaf
Schnappen Sie sich eine Seite und greifen Sie sie dann zufällig für 2-5 Sekunden zu.
Captcha-Erkennung oder Code-Empfangsplattform
Verwenden Sie den Verifizierungscode, um den Verifizierungscode zu identifizieren, oder verwenden Sie die Codeempfangsplattform, um den Verifizierungscode zu identifizieren.
PhantomJS,Selen
Verwenden Sie das Crawler-Framework, das mit dem Browser geliefert wird, um die Seite zu crawlen, egal wie komplex die Verschlüsselung ist, der Browser wird sie für Sie dekodieren.
Massenkonten
Erstellen Sie eine große Anzahl von Cookies mit gefälschten Konten, die von Crawlern verwendet werden können.
# Praxis
Wenn ich hier schreibe, werden einige Leute definitiv sagen, dass ich paddele, * wirklich nein ah*, die vorherige Zusammenfassung kann nicht erweitert werden, wenn der Inhalt nicht klar geschrieben ist, das Folgende ist ein Crawler, den ich kürzlich gemacht habe, voller Trockenwaren.
Der gesamte in diesem Artikel verwendete Code: {% btn https://cloud.tstrs.me/?/%E7%A8%80%E6%9C%89%E8%B5%84%E6%BA%90/%E7%88%AC%E8%99%AB/bookset.me/, Code download, download fa-lg fa-fw %}
Zielanalyse
Das Ziel dieses Crawls ist bookset.me, das ist eine E-Book-Website mit neuen Buch-Updates, das Backend ist WordPress + PHP, und die Links zur Detailseite sind auch sehr regelmäßig, wie zum Beispiel:
https://bookset.me/6647.html
Öffnen Sie den Link ist *Was Philosophen denken Yang Roman (Autor) *, die Bücher auf dieser Website seit mehr als einem halben Jahr sind drei Versionen nebeneinander, mobi + epub + azw3 so, spezifisch für eine einzelne Datei Download-Link ist:
http://download.bookset.me/d.php?f=2017/10/ Yang-Roman - Was Philosophen denken - 9787559609939.epub
Ist es nicht sehr regelmäßig? Solange es eine Regelmäßigkeit gibt, kann man klettern.
Voraussetzungen
Hardware-Abschnitt:
Ein Linux-Server
Öffentliches IP-IP-Breitband
Xiaomi-Router (wenn es sich um eine andere Marke handelt, garantiert der Code nicht, dass er ordnungsgemäß funktioniert)
Software-Abschnitt:
Bildschirm
Python 2 und Python 3 (sofern nicht anders angegeben, wird der folgende Code in Python 3 ausgeführt)
Flussdiagramm
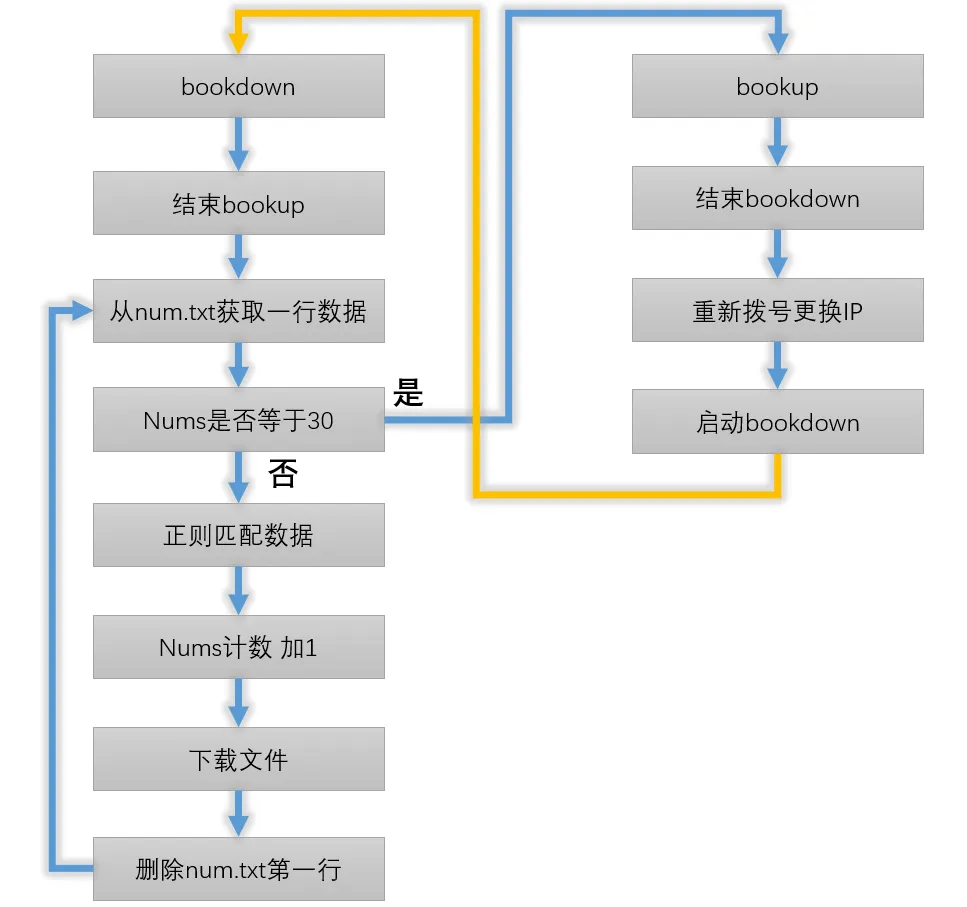
Download-Links crawlen
Da der Download-Link und die Hauptseite getrennt sind, sodass Sie aus Sicherheitsgründen auf unterschiedliche Anti-Crawler-Strategien stoßen können, besteht die von mir gewählte Lösung darin, zuerst alle Download-Links zu crawlen und sie dann stapelweise herunterzuladen und den folgenden Code zu verwenden, um die Download-Links aller E-Books von Seite 1 bis 133 zu crawlen und sie in derselben Ordnernummer zu speichern.txt:
# Codierung: UTF-8
# !/usr/bin/python3
Importieren von Betriebssystemen
sys importieren
JSON importieren
urllib.request importieren
Import Re
urllib importieren
Zeit importieren
Für Liste1 im Bereich (1,133,1):
Zahlen = []
url = r'https://bookset.me/page/%s' %-Liste1
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, wie Gecko) Chrome/55.0.2883.87 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
number = re.findall(r'<h3><a href="(.+?)" alt="', html)
numbers.extend(Anzahl)
Für Seiten in Zahlen:
url = r'%s' % Seiten
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, wie Gecko) Chrome/55.0.2883.87 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
dlinks = re.findall(r'd.php(.+?) mbm-book-download-links-text', html)
name = re.findall(r</small>' <span class="muted">(.+?)'</span>, html)
name = name[0]
dlinks1 = []
Typ = []
Für p in dlinks:
sx1 = p.replace('"><span class="', "")
sx2 = sx1[-5:]
dlinks1.append(sx1)
Typ.append(sx2)
Für (dlinks2, type1) in zip(dlinks1, type):
print(Name)
links = 'wget --user-agent="Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 wie Mac OS X) AppleWebKit/604.1.38 (KHTML, wie Gecko) Version/11.0 Mobile/15A372 Safari/604.1" -O /root/books/' + Name + '/' + Name + type1 + ' http://download.bookset.me/d.php' + dlinks2
fileObject = open('num.txt', 'a')
fileObject.write(Links)
fileObject.write('\n')
fileObject.close()
Wenn Sie zu faul zum Crawlen sind, können Sie die Dateien, die ich hier gecrawlt habe, direkt herunterladen: {% btn https://cloud.tstrs.me/?/%E7%A8%80%E6%9C%89%E8%B5%84%E6%BA%90/%E7%88%AC%E8%99%AB/bookset.me/bookset.me-2019-04-28.txt, download, download fa-lg fa-fw %}
Diese Datei wird in folgendem Format geöffnet:
wget --user-agent="Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 wie Mac OS X) AppleWebKit/604.1.38 (KHTML, wie Gecko) Version/11.0 Mobile/15A372 Safari/604.1" -O /root/books/Cotton Empire/Cotton Empire.epub http://download.bookset.me/d.php?f=2019/4/%5B %5D Sven Beckett-Cotton Empire-9787513923927.epub
wget --user-agent="Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 wie Mac OS X) AppleWebKit/604.1.38 (KHTML, wie Gecko) Version/11.0 Mobile/15A372 Safari/604.1" -O /root/books/Cotton Empire/Cotton Empire.azw3 http://download.bookset.me/d.php?f=2019/4/%5B %5D Sven Beckett-Cotton Empire-9787513923927.azw3
wget --user-agent="Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 wie Mac OS X) AppleWebKit/604.1.38 (KHTML, wie Gecko) Version/11.0 Mobile/15A372 Safari/604.1" -O /root/books/cotton empire/cotton empire.mobi http://download.bookset.me/d.php?f=2019/4/%5B U.S. %5D Sven Beckett - Cotton Empire - 9787513923927.mobi
Jede Zeile dieser langen Liste kann direkt heruntergeladen werden, indem sie direkt in die Befehlszeilenschnittstelle des Linux-Systems kopiert wird (erfordert den Ordner books). Aber Sie können hier nicht verrückt herunterladen, da der Download-Service der Bootset-Website über Anti-Crawler-Maßnahmen verfügt, der Pegel jedoch nicht sehr hoch ist, nur Limit IP und Limit Frequency.
1. Jede IP kann nicht mehr als 30 Dateien hintereinander herunterladen.
2. Das Intervall zwischen kontinuierlichen Download-Dateien jeder IP darf nicht weniger als 10 Sekunden betragen.
3. Wenn es weniger als 10 Sekunden sind, können nur 5 Dateien heruntergeladen werden, und die sechste beginnt mit dem Blockieren der IP.
Automatische Wahlwiederholung
Der Download-Code ist einfach zu schreiben, aber wie kann man diese drei Einschränkungen durchbrechen? Die Hauptsache ist, Ihre eigene IP zu ändern. Und ich bin eine große Anzahl von Download-Dingen, so dass Proxy-IP nicht machbar ist, es ist sehr zufällig, dass mein Breitband eine öffentliche Netzwerk-IP hat, ich muss nur erneut wählen, um die IP zu wechseln, und es durchbricht den Block in Verkleidung.
Der Router, den ich verwende, ist ein Xiaomi-Router, unter normalen Umständen erfordert die Wahlwiederholung eine manuelle Anmeldung im Hintergrund, das Trennen der Verbindung zuerst und dann das erneute Verbinden, aber das Automatisierungstool ist zu mühsam, um manuell zu arbeiten.
Ich habe eine Lösung auf dem Blog [eines Affen] (https://www.92ez.com) gefunden, indem ich mich mit python beim Xiaomi-Router angemeldet und die Wahlwiederholung wiederholt habe. Der Code ist auf dieser [Seite] (https://www.92ez.com/?action=show&id=23405) zu lang, um ihn hier einzufügen, 'mi.py' in den zuvor bereitgestellten Download-Link.
Der Code wird mit python2 ausgeführt und hat nur zwei Funktionen, die automatische Wahlwiederholung und den Neustart des Routers. Der Befehl zur Wahlwiederholung lautet:
python2 mi.py 192.168.31.1 <password> wieder verbinden
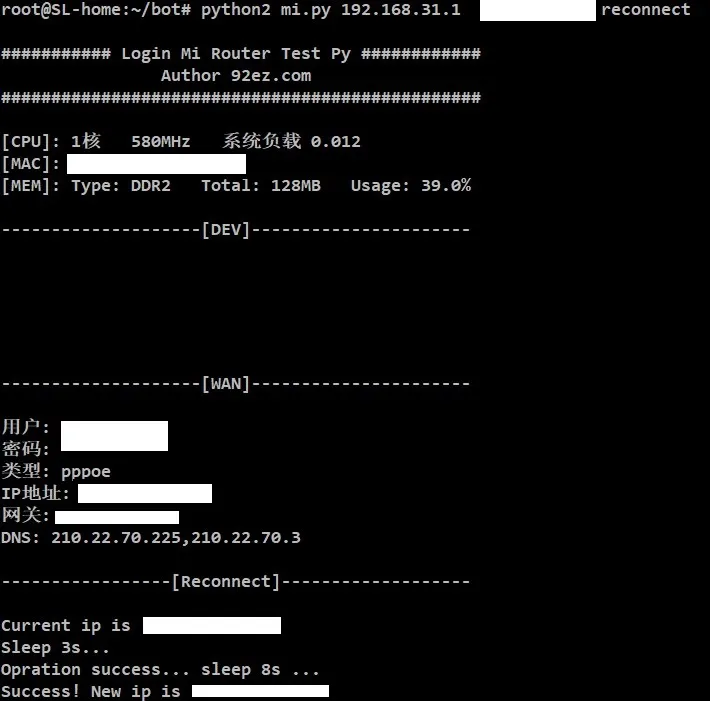
Nach dem Ende des Betriebs wird die IP umgeschaltet, und zu diesem Zeitpunkt können Sie tun, was Sie wollen.
P.S
Ich bin hier auf einen seltsamen Fehler gestoßen, ich kann den Crawler nicht sofort nach dem Trennen und erneuten Verbinden starten, sonst bekomme ich immer wieder 302 Sprünge zu einem seltsamen Domainnamen und Zeitüberschreitung.
--2019-05-04 02:19:27-- http://download.bookset.me/d.php?f=2019/3/%E7%91%9E%C2%B7%E8%BE%BE%E5%88%A9%E6%AC%A7-%E5%80%BA%E5%8A%A1%E5%8D%B1%E6%9C%BA-9787521700077.azw3
Lösen von download.bookset.me (download.bookset.me)... 104.31.84.161, 104.31.85.161, 2606:4700:30::681F:55A1, ...
Verbindung zu download.bookset.me (download.bookset.me)|104.31.84.161|:80... verbunden.
HTTP-Anfrage gesendet, wartet auf Antwort... 302 vorübergehend umgezogen
Wohnort: http://sh.cncmax.cn/ [folgende]
--2019-05-04 02:19:27-- http://sh.cncmax.cn/
Lösen von sh.cncmax.cn (sh.cncmax.cn)... 210.51.46.116
Verbindung zu sh.cncmax.cn (sh.cncmax.cn)|210.51.46.116|:80... verbunden.
HTTP-Anfrage gesendet, wartet auf Antwort... 302 vorübergehend umgezogen
Wohnort: http://sh.cncmax.cn/ [folgende]
--2019-05-04 02:19:27-- http://sh.cncmax.cn/
Verbindung zu sh.cncmax.cn (sh.cncmax.cn)|210.51.46.116|:80... fehlgeschlagen: Zeitüberschreitung der Verbindung.
Lösen von sh.cncmax.cn (sh.cncmax.cn)... 210.51.46.116
Verbindung zu sh.cncmax.cn (sh.cncmax.cn)|210.51.46.116|:80... fehlgeschlagen: Zeitüberschreitung der Verbindung.
Wiederholung.
--2019-05-04 02:23:50-- (Versuch: 2) http://sh.cncmax.cn/
Verbindung zu sh.cncmax.cn (sh.cncmax.cn)|210.51.46.116|:80... fehlgeschlagen: Zeitüberschreitung der Verbindung.
Wiederholung.
Dieser Domainname kann nicht geöffnet werden, ich habe whois überprüft, der Domainname gehört Unicom, aber in einem [Dokument] (http://www.sarft.gov.cn/shanty/resource/appendix/2008/07/03/20080711145144410222.doc) der staatlichen Verwaltung für Radio und Fernsehen ist der Dienst, der diesem Domainnamen entspricht, "Broadband My World Shanghai", ich denke, dies sollte der Geist des Betreibers sein. Dies entspricht einem Man-in-the-Middle-Angriff, und es wird empfohlen, dass jeder https verwendet, auch wenn es sich um eine Download-Site handelt.
Batch-Download
Aufgrund von 302 ist mein Code in zwei Teile unterteilt. Der erste Teil wird heruntergeladen, der zweite Teil beendet den Download, ändert die IP und startet den Download erneut.
1.Da die Daten in meinen vorherigen Schritten nicht sehr sauber gereinigt wurden und einige Zeichen redundant waren, hatte der Crawler beim automatischen Herunterladen Fehler beim Erstellen neuer Ordner, daher war es notwendig, replace zu verwenden, um diese chinesisch-englischen Symbole zu bereinigen.
# Codierung: UTF-8
# !/usr/bin/python3
Importieren von Betriebssystemen
sys importieren
JSON importieren
urllib.request importieren
Import Re
urllib importieren
Zeit importieren
Zufällig importieren
Anzahl = 0
Datei = open("num.txt")
os.system('screen -X -S bookup quit ')
für Zeile in file.readlines():
Wenn Anzahl == 30:
os.system('cd /root/bot & screen -S bookup -d -m -- sh -c "python 2.py; exec $SHELL"')
brechen
name = re.findall(r'/root/books/(.*?) http', Zeile)
name = name[0]
name = name.replace(' ', "-")
name = name.replace('-', "")
name = name.replace('(', "")
name = name.replace(')', "")
name = name.replace(':', "-")
name = name.replace(':', "-")
name = name.replace('(', "")
name = name.replace(')', "")
name = name.replace('—', "-")
name = name.replace(',', ",")
name = name.replace('。 ', ".")
name = name.replace('! ', "")
name = name.replace('!', "")
name = name.replace('? ', "")
name = name.replace('?', "")
name = name.replace('【', "")
name = name.replace('】', "")
name = name.replace('"', "")
name = name.replace('"', "")
name = name.replace(''', "")
name = name.replace(''', "")
name = name.replace('"', "")
name = name.replace('\'', "")
name = name.replace('、', "-")
name1 = re.findall(r'^(.*?) /', Name)
name1 = name1[0]
os.system('mkdir /root/books/%s' % name1)
line1 =re.findall(r'http(.*?) $', Zeile)
Zeile1 = Zeile1[0]
Anzahl = Anzahl + 1
link = 'wget --user-agent="Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 wie Mac OS X) AppleWebKit/604.1.38 (KHTML, wie Gecko) Version/11.0 Mobile/15A372 Safari/604.1" -O /root/books/'+name+" 'http"+line1+"'"
Zeit.Schlaf(12)
os.system(link)
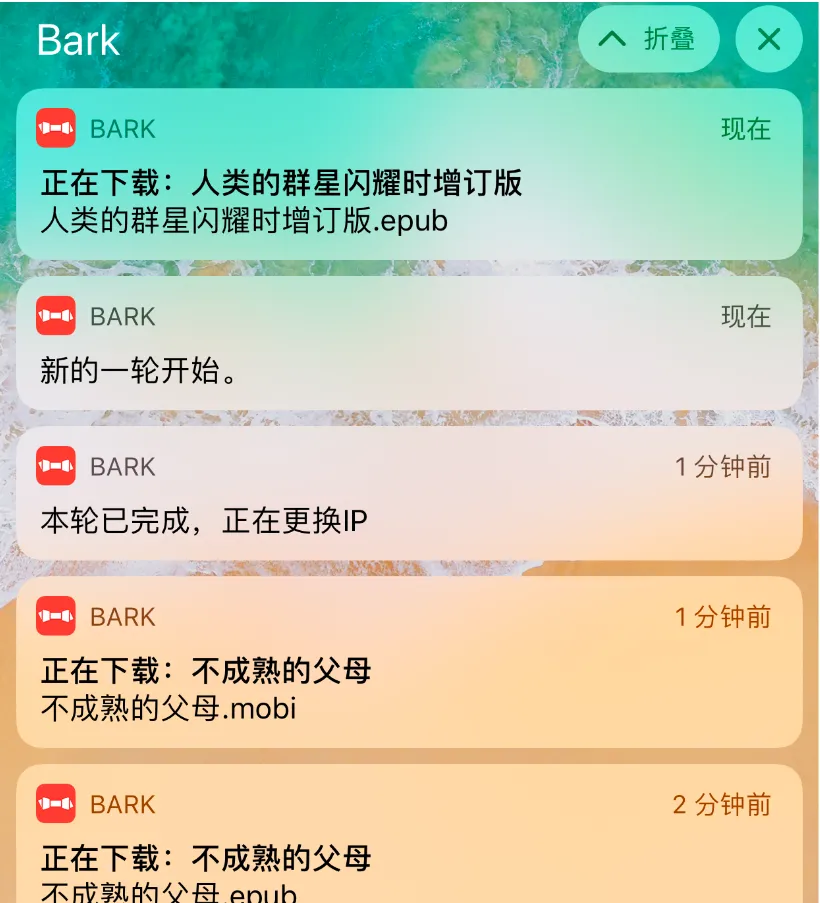
os.system("curl '<you-token>https://api.day.app//downloading:'"+name)
mit open('num.txt', 'r') als fin:
data = fin.read().splitlines(True)
mit open('num.txt', 'w') als fout:
fout.writelines(data[1:])
Die Funktion des Skripts besteht darin, die Zahl .txt Zeile zu lesen, 12 Sekunden zu warten, die Datei herunterzuladen, die gelesene Zeile zu löschen, zu recyceln, 30 hintereinander herunterzuladen, ein anderes Skript zu starten und zu beenden, und schließlich verwende ich den Push-Service von Bark, damit ich bei einem Problem die spezifische Datei finden und das Skript neu starten kann.
*Das Hauptproblem ist der 302-Sprung. *
2. Die Funktion dieses Teils besteht darin, die Ausführung von Skript 1 zu beenden, die Wahlwiederholung, 'time.sleep' für eine Minute zu wiederholen und Skript 1 zu starten.
# Codierung: UTF-8
# !/usr/bin/python3
Importieren von Betriebssystemen
sys importieren
Zeit importieren
os.system('screen -X -S bookdown quit ')
os.system("curl '<you-token>https://api.day.app//round abgeschlossen, IP-Ersatz wird vorgenommen")
os.system("python2 mi.py 192.168.31.1 <password> reconnect")
Zeit.Schlaf(60)
os.system("curl 'https://api.day.app/<you-token>/Beginn einer neuen Runde.") ")
os.system('cd /root/bot & screen -S bookdown -d -m -- sh -c "python 1.py; exec $SHELL"')
Der Vorteil der Verwendung des Bildschirms besteht darin, dass er im Hintergrund ausgeführt werden kann, Sie müssen sich keine Sorgen machen, dass das Skript hängen bleibt, und Sie können auch nach oben klicken, um die Fehlermeldung anzuzeigen.
Um den Download zu starten, verwenden Sie den folgenden Code:
screen -S bookdown -d -m -- sh -c "python 1.py; Exekutive $SHELL"
Einmal gestartet, laufen 1.py und 2.py wie Perpetuum Mobile, bis die Dateien in der Anzahl .txt leer sind.
# Nachtrag
Es macht Spaß, Räder zu machen, einige Bücher sind auch sehr gut, als dieser Artikel fertiggestellt war, hatte ich nicht alle Daten heruntergeladen, nur etwa die Hälfte heruntergeladen, und es wird erwartet, dass es 22 Stunden dauern wird, bis der vollständige Download abgeschlossen ist. Davon sind 2,5 Stunden getrennte Wahlwiederholungen und 15 Stunden Time.Sleep.
Tatsächlich kann der Code vereinfacht werden, und wenn ich def lerne, brauche ich keine zwei Skripte ...
Referenz
Tags :
Urheberrechtshinweis :
Dieser Artikel wurde von SaltyLeo verfasst. Bei Fehlern bitte eine Nachricht hinterlassen. Bei der Reproduktion oder Zitierung dieses Artikels beachten Sie bitte die CC BY-NC-SA Lizenz, die Namensnennung, nichtkommerzielle Nutzung und die gleiche Weitergabe erfordert!Kommentar :
Weiterlesen :


Schreiben Sie selbst Code, um ein unkonventionelles Problem zu lösen.

Das Netzwerk wurde ebenfalls aktualisiert und die Geräte wurden debuggt Was ist, wenn ich auf lokale Dateien im externen Netzwerk zugreifen möchte?

Mit vlmcsd aktivieren
Mehrere effektive kleine Methoden zum Schutz des Computers
Lösen Sie das Software-Flashback-Problem der Store-Download-Version
Inhaltsverzeichnis
 Deutsch
Deutsch 中文
中文 English
English Français
Français 日本語
日本語 Pу́сский язы́к
Pу́сский язы́к 한국어
한국어 Español
EspañolWebsite-Informationen
Tags: 206
Gesamtseitenaufrufe: 12,931,942
Ladezeit: 16.39 ms
Ver : 3.0.1