고급 Python 크롤러 - 획기적인 안티 크롤러
2019-05-05 · 995 · 1 min저는 수집가이고 좋은 자료를 모으고 싶은데 하나씩 다운로드하기에는 너무 시간과 번거로움이 있어서 예전의 API와 크롤러가 있는데 지금은 웹마스터가 점차 저작권 제한을 없애고 있기 때문에 파일 링크만 파싱하는 것이 아니라 자신의 하드 드라이브에 저장하고 싶습니다.
나중에 공유를 위해 클라우드 디스크 TSTR_Cloud를 만들었습니다. 나는 종종 강가를 걷고, 어떻게 신발을 젖지 않을 수 있고, 내 클라우드 디스크도 크롤러에 의해 크롤링되고, 사유화해야하며, 액세스하려면 암호를 사용해야합니다.
하지만 나는 여전히 다른 사이트에서 전자 책을 긁어 모아 현재 52G, 약 5300 부를 저장하고 있습니다.

이 기사의 주요 내용은 안티 크롤러 전략과 안티 크롤러 팁입니다.
# 안티 크롤러
현재 크롤러 방지 조치는 쉬운 것부터 어려운 것까지 다양합니다.
IP
IP 주소 트래픽이 급증하고 IP가 대상 방식으로 차단됩니다.
사용자 에이전트
차단된 인간이 아닌 사용자 에이전트 식별(예: JavaClient 1.6)
빈도
특정 IP의 접속 빈도에 따라 단위 시간에 접속이 너무 빈번하여 차단됩니다.
보안 문자
데이터를 가져오려면 보안 문자가 필요합니다.
js 암호화
JS는 데이터를 암호화합니다.
쿠키
크롤링하려면 계정에 로그인해야 합니다.
위의 모든 것은 다른 큰 사람들의 경험을 기반으로하며, 지금까지 처음 세 가지만 만났습니다.
# 안티 안티 크롤러
프록시 IP
프록시 IP를 사용하여 IP를 기반으로 블록을 식별할 확률을 줄입니다.
useragent 시뮬레이션
"Mozilla / 5.0"과 같은 사용자 에이전트를 사용하면 웹 사이트 거부 가능성이 줄어 듭니다.
예정된 수면
페이지를 잡은 다음 2-5초 동안 무작위로 잡습니다.
Captcha 인식 또는 코드 수신 플랫폼
확인 코드를 사용하여 식별하거나 코드 수신 플랫폼을 사용하여 확인 코드를 식별합니다.
팬텀JS,셀레늄
브라우저와 함께 제공되는 크롤러 프레임워크를 사용하여 페이지를 크롤링하면 암호화가 아무리 복잡하더라도 브라우저가 이를 디코딩합니다.
대량 계정
크롤러가 사용할 수 있도록 가짜 계정으로 많은 수의 쿠키를 만듭니다.
# 연습
여기에 글을 쓰면, 어떤 사람들은 분명히 내가 노를 젓고 있다고 말할 것입니다, * 정말 아니 아 *, 내용이 명확하게 쓰여지지 않으면 이전 시놉시스를 확장 할 수 없습니다, 다음은 내가 최근에 만든 크롤러입니다, 건조 제품으로 가득합니다.
이 문서에 사용된 모든 코드: {% btn https://cloud.tstrs.me/?/%E7%A8%80%E6%9C%89%E8%B5%84%E6%BA%90/%E7%88%AC%E8%99%AB/bookset.me/, 코드 다운로드, 다운로드 fa-lg fa-fw %}
타겟 분석
이 크롤링의 대상은 bookset.me이며, 이는 새 책 업데이트가 포함된 전자책 웹사이트이며, 백엔드는 WordPress + PHP이며, 세부 정보 페이지에 대한 링크도 다음과 같이 매우 규칙적입니다.
https://bookset.me/6647.html
링크를 열면 * 철학자들이 생각하는 것 양 소설 (저자) *, 반년 이상이 웹 사이트의 책은 mobi + epub + azw3의 세 가지 버전이 공존하고 있으므로 단일 파일 다운로드 링크에 대한 구체적인 내용은 다음과 같습니다.
http://download.bookset.me/d.php?f=2017/10/ 양 소설 - 철학자들이 생각하는 것 - 9787559609939.epub
매우 규칙적이지 않습니까? 규칙적인 한 등반할 수 있습니다.
요구 사항
하드웨어 섹션:
리눅스 서버
공용 IP IP 광대역
Xiaomi 라우터 (다른 브랜드 인 경우 코드가 제대로 작동한다고 보장하지 않음)
소프트웨어 섹션:
화면
Python 2 및 Python 3 (달리 명시되지 않는 한, 다음 코드는 Python 3에서 실행됨)
순서도
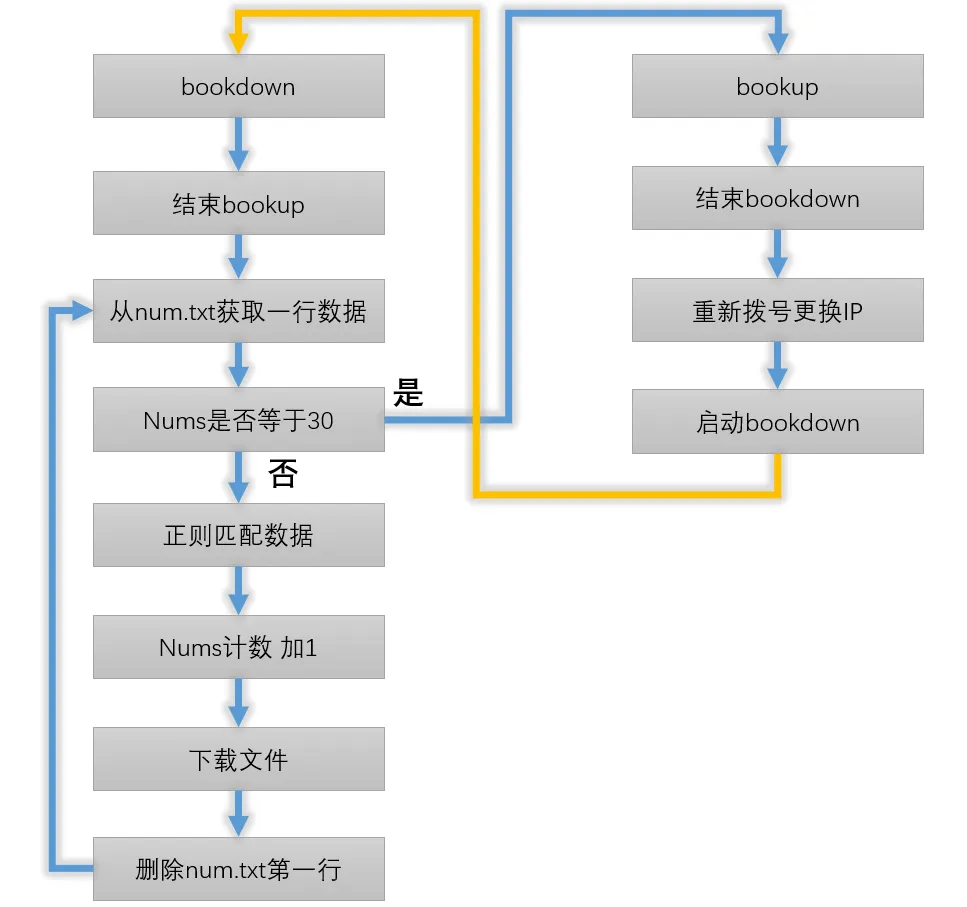
크롤링 다운로드 링크
다운로드 링크와 메인 사이트가 분리되어 있기 때문에 안전을 위해 다른 안티 크롤러 전략이 발생할 수 있으므로 내가 선택한 솔루션은 먼저 모든 다운로드 링크를 크롤링 한 다음 일괄 적으로 다운로드하고 다음 코드를 사용하여 .txt모든 전자 책의 다운로드 링크를 크롤링하는 것입니다.
# 코딩: UTF-8
# !/usr/bin/python3
OS 가져오기
수입 sys
json 가져 오기
urllib.request 가져 오기
수입 재
urllib 가져 오기
가져오기 시간
range(1,133,1)의 list1의 경우:
숫자 = []
url = r'https://bookset.me/page/%s' % 목록1
headers = {'사용자 에이전트': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Gecko와 같은 KHTML) Chrome/55.0.2883.87 Safari/537.36'}
요청 = urllib.request.Request(url=url, headers=headers)
해상도 = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
number = re.findall(r'<h3><a href="(.+?)" alt="', html)
numbers.extend(숫자)
숫자로 된 페이지의 경우:
URL = r'%s' % 페이지
headers = {'사용자 에이전트': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Gecko와 같은 KHTML) Chrome/55.0.2883.87 Safari/537.36'}
요청 = urllib.request.Request(url=url, headers=headers)
해상도 = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
dlinks = re.findall(r'd.php(.+?) mbm-book-download-links-text', html)
name = re.findall(r</small>' <span class="muted">(.+?)'</span>, html)
이름 = 이름[0]
dlinks1 = []
유형 = []
dlinks의 p의 경우:
SX1 = p.replace('"><span class="', "")
SX2 = SX1[-5:]
dlinks1.append(sx1)
유형.append(SX2)
zip(dlinks1, type)의 (dlinks2, type1)의 경우:
인쇄(이름)
links = 'wget --user-agent="Mozilla/5.0 (iPhone; CPU Mac OS X와 같은 iPhone OS 11_0) AppleWebKit/604.1.38 (KHTML, Gecko와 같은) Version/11.0 Mobile/15A372 Safari/604.1" -O /root/books/' + name + '/' + name + type1 + ' http://download.bookset.me/d.php' + dlinks2
fileObject = open('num.txt', 'a')
fileObject.write(링크)
fileObject.write('\n')
fileObject.close()를 호출합니다.
크롤링하기에는 너무 게으른 경우 여기에서 크롤링 한 파일을 직접 다운로드 할 수 있습니다 : { % btn https://cloud.tstrs.me/?/%E7%A8%80%E6%9C%89%E8%B5%84%E6%BA%90/%E7%88%AC%E8%99%AB/bookset.me/bookset.me-2019-04-28.txt, 다운로드, 다운로드 fa-lg fa-fw %}
이 파일은 다음 형식으로 열립니다.
wget --user-agent="Mozilla/5.0 (iPhone; CPU 아이폰 OS 11_0 맥 OS X) AppleWebKit / 604.1.38 (KHTML, 도마뱀처럼) 버전 / 11.0 모바일 / 15A372 Safari / 604.1 "-O / 루트 / 책 / 코튼 제국 / 코튼 제국.epub http://download.bookset.me/d.php?f=2019/4/%5B %5D 스벤 베켓-코튼 엠파이어-9787513923927.epub
wget --user-agent="Mozilla/5.0 (iPhone; CPU 아이폰 OS 11_0 맥 OS X) AppleWebKit / 604.1.38 (KHTML, 도마뱀처럼) 버전 / 11.0 모바일 / 15A372 Safari / 604.1 "-O / 루트 / 책 / 코튼 제국 / 코튼 제국.azw3 http://download.bookset.me/d.php?f=2019/4/%5B %5D 스벤 베켓-코튼 엠파이어-9787513923927.azw3
wget --user-agent="Mozilla/5.0 (iPhone; CPU 아이폰 OS 11_0 맥 OS X) AppleWebKit/604.1.38 (KHTML, 도마뱀붙이처럼) 버전/11.0 모바일/15A372 사파리/604.1" -O /root/books/cotton empire/cotton empire.mobi http://download.bookset.me/d.php?f=2019/4/%5B 미국 %5D 스벤 베켓 - 코튼 엠파이어 - 9787513923927.mobi
이 긴 목록의 각 줄은 리눅스 시스템 명령줄 인터페이스(books 폴더 필요)에 직접 복사하여 직접 다운로드할 수 있습니다. 그러나 부트 세트 웹 사이트의 다운로드 서비스에는 크롤러 방지 조치가 있지만 레벨은 그리 높지 않고 * 제한 IP * 및 * 제한 빈도 *만 있기 때문에 여기에서 미친 듯이 다운로드 할 수 없습니다.
1. 각 IP는 30개 이상의 파일을 연속으로 다운로드할 수 없습니다.
2. 각 IP의 연속 다운로드 파일 사이의 간격은 10초 이상이어야 합니다.
3. 10초 미만인 경우 5개의 파일만 다운로드할 수 있으며 여섯 번째 파일은 IP 차단을 시작합니다.
자동 재다이얼
다운로드 코드는 작성하기 쉽지만 이 세 가지 제한 사항을 깨는 방법은 무엇입니까? 가장 중요한 것은 자신의 IP를 수정하는 것입니다. 그리고 나는 많은 수의 다운로드 물건이므로 프록시 IP가 실현 가능하지 않으며, 내 광대역에 공용 네트워크 IP가 있다는 것은 매우 우연의 일치이며, IP를 전환하기 위해 다시 전화를 걸기 만하면되며, 위장하여 블록을 돌파합니다.
내가 사용하는 라우터는 Xiaomi 라우터이며 정상적인 상황에서 재다이얼하려면 백그라운드에 수동으로 로그인하고 먼저 연결을 끊었다가 다시 연결해야 하지만 자동화 도구는 수동으로 작동하기에는 너무 번거롭습니다.
[원숭이] (https://www.92ez.com) 블로그에서 * python *을 사용하여 Xiaomi 라우터에 로그인하고 다시 전화를 걸었습니다. 이 [페이지] (https://www.92ez.com/?action=show&id=23405)의 코드가 너무 길어서 여기에 붙여 넣을 수 없습니다. 'mi.py' 이전에 제공된 다운로드 링크에서.
이 코드는 python2를 사용하여 실행되며 자동 재다이얼 및 라우터 재부팅의 두 가지 기능만 있습니다. 재다이얼 명령은 다음과 같습니다.
python2 mi.py 192.168.31.1 <password> 다시 연결
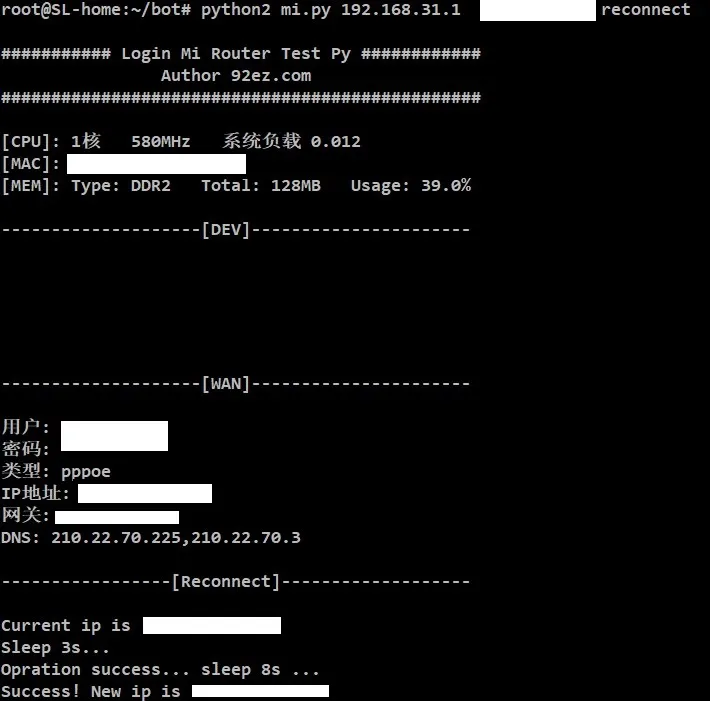
작업 종료 후 IP가 전환되며 이때 원하는 모든 작업을 수행할 수 있습니다.
PS
나는 이상한 버그에 부딪쳤다, 나는 연결을 끊고 다시 연결 한 직후에 크롤러를 시작할 수 없다, 그렇지 않으면 나는 이상한 도메인 이름과 시간 초과에 302 점프를 계속할 것이다.
--2019-05-04 02:19:27-- http://download.bookset.me/d.php?f=2019/3/%E7%91%9E%C2%B7%E8%BE%BE%E5%88%A9%E6%AC%A7-%E5%80%BA%E5%8A%A1%E5%8D%B1%E6%9C%BA-9787521700077.azw3
download.bookset.me 해결(download.bookset.me)... 104.31.84.161, 104.31.85.161, 2606:4700:30::681f:55a1, ...
download.bookset.me 에 연결 중(download.bookset.me)|104.31.84.161|:80... 연결.
HTTP 요청이 전송되어 응답을 기다리는 중... 302 임시로 이동됨
위치: http://sh.cncmax.cn/ [팔로잉]
--2019-05-04 02:19:27-- http://sh.cncmax.cn/
sh.cncmax.cn 해결(sh.cncmax.cn)... 210.51.46.116
sh.cncmax.cn 에 연결 중(sh.cncmax.cn)|210.51.46.116|:80... 연결.
HTTP 요청이 전송되어 응답을 기다리는 중... 302 임시로 이동됨
위치: http://sh.cncmax.cn/ [팔로잉]
--2019-05-04 02:19:27-- http://sh.cncmax.cn/
sh.cncmax.cn 에 연결 중(sh.cncmax.cn)|210.51.46.116|:80... failed: 연결 시간이 초과되었습니다.
sh.cncmax.cn 해결(sh.cncmax.cn)... 210.51.46.116
sh.cncmax.cn 에 연결 중(sh.cncmax.cn)|210.51.46.116|:80... failed: 연결 시간이 초과되었습니다.
재시도.
--2019-05-04 02:23:50-- (시도: 2) http://sh.cncmax.cn/
sh.cncmax.cn 에 연결 중(sh.cncmax.cn)|210.51.46.116|:80... failed: 연결 시간이 초과되었습니다.
재시도.
이 도메인 네임은 열 수 없습니다, 나는 whois를 확인, 도메인 이름은 유니콤에 속하지만, 라디오 및 텔레비전 국가 관리국의 [문서] (http://www.sarft.gov.cn/shanty/resource/appendix/2008/07/03/20080711145144410222.doc)에서이 도메인 이름에 해당하는 서비스는 '광대역 마이 월드 상하이', 나는 이것이 운영자의 유령이어야한다고 생각합니다. 이는 메시지 가로채기(man-in-the-middle) 공격에 해당하며, 다운로드 사이트라도 누구나 https를 사용하는 것이 좋습니다.
일괄 다운로드
302 때문에 코드는 두 부분으로 나뉩니다. 첫 번째 부분이 다운로드되고 두 번째 부분이 다운로드를 종료하고 IP를 변경하고 다운로드를 다시 시작합니다.
1.이전 단계의 데이터가 매우 깔끔하게 정리되지 않았고 일부 문자가 중복되었기 때문에 크롤러가 자동으로 다운로드할 때 새 폴더를 만들 때 오류가 발생하므로 replace를 사용하여 중국어 영어 기호를 정리해야 했습니다.
# 코딩: UTF-8
# !/usr/bin/python3
OS 가져오기
수입 sys
json 가져 오기
urllib.request 가져 오기
수입 재
urllib 가져 오기
가져오기 시간
임의 가져 오기
숫자 = 0
파일 = open("num.txt")
os.system('화면 -X -S 북업 종료')
file.readlines()의 라인에 대해:
nums == 30인 경우:
os.system('cd /root/bot && screen -S bookup -d -m -- sh -c "python 2.py; exec $SHELL"')
휴식
이름 = re.findall(r'/root/books/(.*?) http', line)
이름 = 이름[0]
이름 = name.replace(' ', "-")
이름 = name.replace('-', "")
이름 = name.replace('(', "")
이름 = name.replace(')', "")
이름 = name.replace(':', "-")
이름 = name.replace(':', "-")
이름 = name.replace('(', "")
이름 = name.replace(')', "")
이름 = name.replace('—', "-")
이름 = name.replace(',', ",")
name = name.replace('。 ', ".")
이름 = name.replace('! ', "")
이름 = name.replace('!', "")
이름 = name.replace('? ', "")
이름 = name.replace('?', "")
이름 = name.replace('【', "")
이름 = name.replace('】', "")
이름 = name.replace('"', "")
이름 = name.replace('"', "")
이름 = name.replace(''', "")
이름 = name.replace(''', "")
이름 = name.replace('"', "")
이름 = name.replace('\'', "")
이름 = name.replace('、', "-")
name1 = re.findall(r'^(.*?) /', 이름)
이름1 = 이름1[0]
os.system('mkdir /root/books/%s' % 이름1)
line1 =re.findall(r'http(.*?) $', 줄)
라인1 = 라인1[0]
숫자 = 숫자 + 1
link = 'wget --user-agent="Mozilla/5.0 (iPhone; CPU Mac OS X와 같은 iPhone OS 11_0) AppleWebKit/604.1.38 (KHTML, Gecko와 같은) Version/11.0 Mobile/15A372 Safari/604.1" -O /root/books/'+name+" 'http"+line1+"'"
시간.수면(12)
os.system(링크)
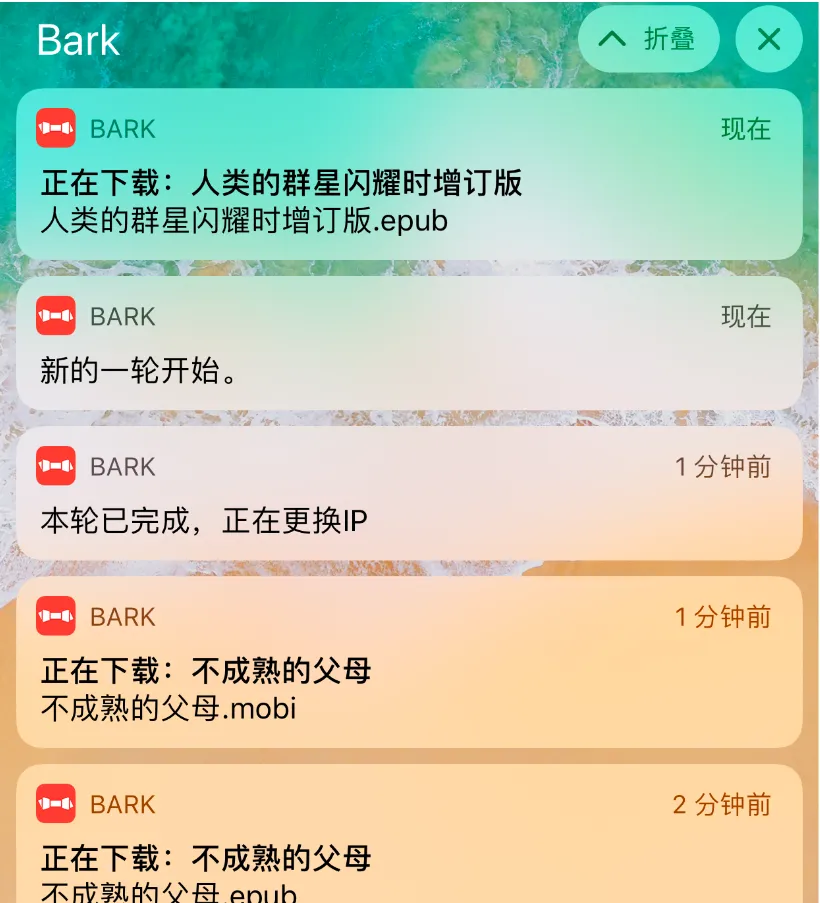
os.system("컬 '<you-token>https://api.day.app//downloading:'"+이름)
open('num.txt', 'r')을 fin으로 사용:
데이터 = fin.read().splitlines(참)
open('num.txt', 'w')를 fout으로 사용:
fout.writelines(데이터[1:])
스크립트의 기능은 num .txt 한 줄씩 읽고, 12 초 동안 기다렸다가 파일을 다운로드하고, 읽은 줄을 삭제하고, 재활용하고, 30 개를 연속으로 다운로드하고, 다른 스크립트를 시작하고 종료하고, 마지막으로 Bark의 푸시 서비스를 사용하여 문제가 있으면 특정 파일을 찾아 스크립트를 다시 시작할 수 있습니다.
* 가장 큰 문제는 302 점프입니다. *
2. 이 부분의 기능은 스크립트 1의 실행을 종료하고 1분 동안 'time.sleep'을 재다이얼한 다음 스크립트 1을 시작하는 것입니다.
# 코딩: UTF-8
# !/usr/bin/python3
OS 가져오기
수입 sys
가져오기 시간
os.system('화면 -X -S 북다운 종료')
os.system("curl '<you-token>https://api.day.app//round 완료, IP 교체 중")
os.system("python2 mi.py 192.168.31.1 <password> 다시 연결")
시간.수면(60)
os.system("curl 'https://api.day.app/<you-token>/새 라운드 시작.") ")
os.system('cd /root/bot && screen -S bookdown -d -m -- sh -c "파이썬 1.py; exec $SHELL"')
화면 사용의 장점은 백그라운드에서 실행할 수 있고 스크립트가 중단되는 것에 대해 걱정할 필요가 없으며 오류 메시지를 보기 위해 ssh를 실행할 수도 있다는 것입니다.
다운로드를 시작하려면 다음 코드를 사용합니다.
화면 -S bookdown -d -m -- sh -c "파이썬 1.py; exec $SHELL"
일단 시작되면 1.py 및 2.py 파일이 숫자 .txt에서 비워질 때까지 영구 모션 머신처럼 실행됩니다.
# 포스트 스크립트
바퀴를 만드는 것도 재미있고, 책도 아주 좋고, 이 글이 완성되었을 때 모든 데이터를 다운로드하지 않고 절반 정도만 다운로드했으며 전체 다운로드를 완료하는 데 22시간이 걸릴 것으로 예상됩니다. 이 중 2.5 시간은 연결이 끊어진 재 다이얼이고 15 시간은 time.sleep입니다.
사실, 코드는 단순화 될 수 있으며, def를 배울 때 두 개의 스크립트가 필요하지 않습니다 ...
태그 :
저작권 공지 :
이 글은 SaltyLeo가 쓴 것입니다, 내용에 오류가 있다면 의견을 남겨주세요. 이 글은 CC BY-NC-SA 라이선스를 준수하여 재게시 또는 인용할 때는 필자를 언급하고, 상업적 용도로 사용하지 않아야 하며, 동일한 방식으로 공유되어야 합니다!댓글 :
더 읽기 :


SSL 인증서를 갱신하는 몇 가지 방법
좋은 RSS 도구: RSSHub
최근에 i-book.in을 재설계하고 자동화 스크립트를 업데이트했습니다. 특정 코드를 게시하지는 않지만 GitHub에서 모두 사용할 수 있습니다.
이 문서는 엄격한 자습서가 아니라 기록 목적으로만 사용됩니다. 내 방법을 따르면 컴퓨터가 BOOM될 수 있기 때문입니다.
최근 파이썬 크롤러를 배우고 있는데 가장 기본이 되는 것은 requests 라이브러리이고 설치 명령어는 매우 간단하다.
 한국어
한국어 中文
中文 English
English Français
Français Deutsch
Deutsch 日本語
日本語 Pу́сский язы́к
Pу́сский язы́к Español
Español사이트 정보
태그: 210
총 페이지 조회수: 12,890,374
로딩 시간: 15.63 ms
Ver : 4.0.1