Python クローラー アドバンスド - 画期的なアンチクローラー
2019-05-05 · 994 · 2 min私はコレクターであり、優れたリソースを収集したいのですが、それらを1つずつダウンロードするのは時間と手間がかかりすぎるため、以前のAPIとクローラーを持っていますが、現在はウェブマスターが徐々に著作権制限を解除しているため、ファイルリンクを解析するだけでなく、自分のハードドライブに保存したいと思います。
その後、共有用のクラウドディスクTSTR_Cloudを作成しました。 私はよく川のそばを歩きます、どうして靴を濡らすことができないのですか、私のクラウドディスクもクローラーによってクロールされています、私はそれを民営化しなければなりません、私はアクセスするためにパスワードを使う必要があります。
しかし、私はまださまざまなサイトから電子書籍をスクレイピングして保存しており、現在は52G、約5300部です。

この記事の主な内容は、アンチクローラー戦略とアンチクローラーのヒントです。
# アンチクローラー
現在のクローラー対策は、簡単なものから難しいものまであります。
IP
IP アドレスのトラフィックが急増し、IP がターゲットを絞った方法でブロックされます。
ユーザーエージェント
ブロックされた人間以外のユーザーエージェントを特定する (例: JavaClient 1.6)
周波数
特定のIPのアクセス頻度に応じて、単位時間内にアクセスが頻繁すぎてブロックされます。
キャプチャ
データを取得するにはキャプチャが必要です。
JS暗号化
データを JS 暗号化します。
クッキー
クロールするにはアカウントにログインする必要があります。
上記のすべては他の大物の経験に基づいており、私はこれまでのところ最初の3つしか遭遇していません。
# アンチクローラー
プロキシ IP
プロキシIPを使用して、IPに基づいてブロックを識別する可能性を減らします。
ユーザーエージェントをシミュレートする
"Mozilla/5.0" のようなユーザエージェントを使えば、ウェブサイトが拒否される確率が低くなります。
スケジュールされた睡眠
ページをつかんでから、ランダムに2〜5秒間つかみます。
キャプチャ認識またはコード受信プラットフォーム
検証コードを使用して確認コードを識別するか、コード受信プラットフォームを使用して検証コードを識別します。
ファントムJS,セレン
ブラウザに付属のクローラーフレームワークを使用してページをクロールし、暗号化がどれほど複雑であっても、ブラウザがページをデコードします。
一括アカウント
クローラーが使用する偽のアカウントを使用して多数のCookieを作成します。
# 練習
ここに書くと、一部の人々は間違いなく私がパドリングしていると言うでしょう、本当にああ、内容が明確に書かれていないと前のあらすじは拡張できません、以下は私が最近作ったクローラーで、乾物でいっぱいです。
この記事で使用されているすべてのコード: {% btn https://cloud.tstrs.me/?/%E7%A8%80%E6%9C%89%E8%B5%84%E6%BA%90/%E7%88%AC%E8%99%AB/bookset.me/、コード ダウンロード、ダウンロード fa-lg fa-fw %}
ターゲット分析
このクロールのターゲットはbookset.meで、これは新しい本の更新を含む電子書籍Webサイトであり、バックエンドはWordPress + PHPであり、詳細ページへのリンクも次のように非常に規則的です。
https://bookset.me/6647.html
リンクを開くことは哲学者がヤン小説(著者)を考えていることであり、半年以上にわたってこのウェブサイト上の本は、共存する3つのバージョンであり、mobi + epub + azw3なので、単一のファイルのダウンロードリンクに固有のものです。
http://download.bookset.me/d.php?f=2017/10/ ヤン小説-哲学者が考えていること-9787559609939.epub
とても定期的ではありませんか? 規則性がある限り、登ることができます。
要件
ハードウェアセクション:
リナックスサーバー
パブリック IP IP ブロードバンド
Xiaomiルーター(別のブランドの場合、コードは正しく機能することを保証するものではありません)
ソフトウェアセクション:
スクリーン
Python 2 と Python 3 (特に明記されていない限り、次のコードは Python 3 で実行されます)
フローチャート
ダウンロードリンクをクロールする
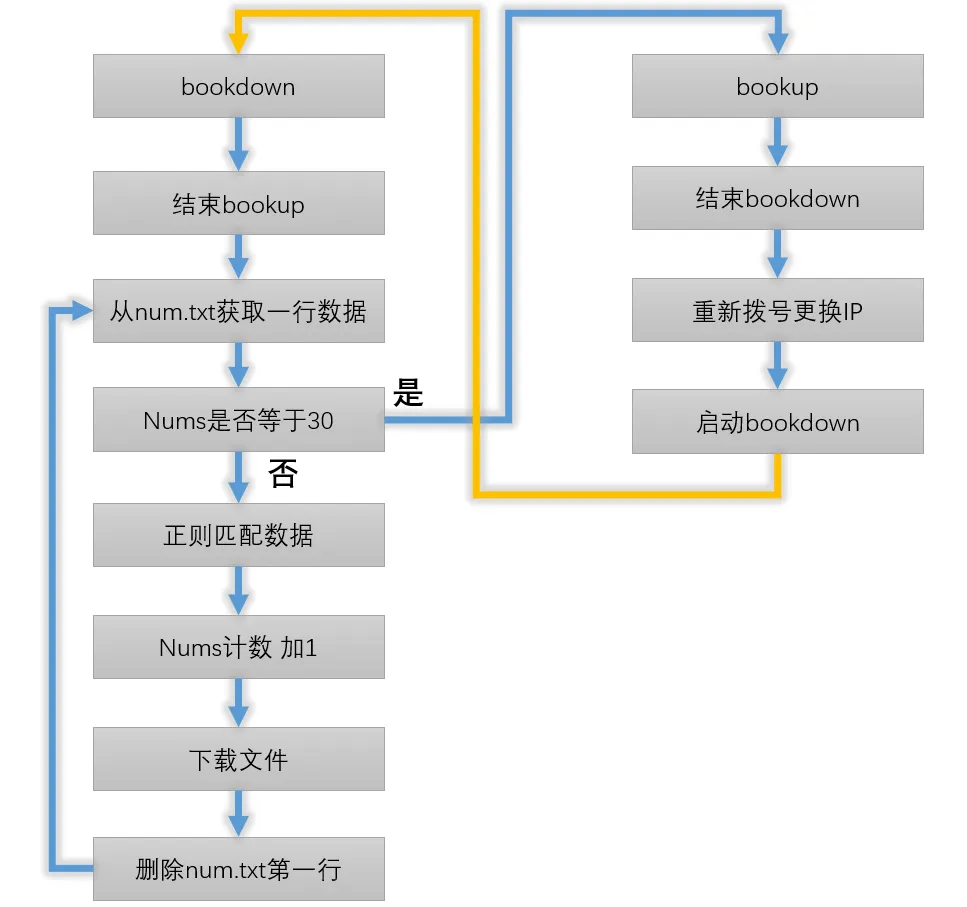
ダウンロードリンクとメインサイトは分離されているため、異なるアンチクローラー戦略に遭遇する可能性があるため、安全のために、私が選択した解決策は、最初にすべてのダウンロードリンクをクロールしてからバッチでダウンロードし、次のコードを使用してすべての電子書籍のダウンロードリンクをページ1から133にクロールし、同じフォルダーnumに保存します.txt
# コーディング: UTF-8
# !/usr/bin/python3
OS のインポート
システムのインポート
JSON をインポートする
インポート urllib.request
インポート再
インポート URLLIB
インポート時間
範囲内のリスト1の場合(1,133,1):
数字 = []
url = r'https://bookset.me/page/%s' % list1
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (ヤモリのような KHTML) Chrome/55.0.2883.87 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
number = re.findall(r'<h3><a href="(.+?)" alt="', html)
数値.拡張(数値)
数字のページの場合:
URL = r'%s' % ページ
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (ヤモリのような KHTML) Chrome/55.0.2883.87 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
dlinks = re.findall(r'd.php(.+?) MBM-book-download-links-text', html)
name = re.findall(r</small>' <span class="muted">(.+?)'</span>, html)
名前 = 名前[0]
dlinks1 = []
タイプ = []
ドリンクのpの場合:
sx1 = p.replace('"><span class="', "")
sx2 = sx1[-5:]
dlinks1.append(sx1)
タイプ.追加(SX2)
(dlinks2, type1) in zip(dlinks1, type):
印刷(名前)
links = 'wget --user-agent="Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 のような Mac OS X) AppleWebKit/604.1.38 (ヤモリのような KHTML) バージョン/11.0 モバイル/15A372 サファリ/604.1" -O /root/books/' + name + '/' + name + type1 + ' http://download.bookset.me/d.php' + ドリンク2
fileObject = open('num.txt', 'a')
fileObject.write(links)
fileObject.write('\n')
fileObject.close()
あなたがクロールするのが面倒な場合は、ここでクロールしたファイルを直接ダウンロードできます:{% btn https://cloud.tstrs.me/?/%E7%A8%80%E6%9C%89%E8%B5%84%E6%BA%90/%E7%88%AC%E8%99%AB/bookset.me/bookset.me-2019-04-28.txt、ダウンロード、ダウンロードfa-lg FA-FW %}
このファイルは次の形式で開きます。
wget --user-agent="Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (ヤモリのような KHTML) バージョン/11.0 モバイル/15A372 サファリ/604.1" -O /root/books/Cotton Empire/Cotton Empire.epub http://download.bookset.me/d.php?f=2019/4/%5B %5D スヴェンベケット-コットンエンパイア-9787513923927.epub
wget --user-agent="Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1" -O /root/books/Cotton Empire/Cotton Empire.azw3 http://download.bookset.me/d.php?f=2019/4/%5B %5D スヴェンベケット-コットン帝国-9787513923927.azw3
wget --user-agent="Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (ヤモリのような KHTML) バージョン/11.0 モバイル/15A372 サファリ/604.1" -O /ルート/ブックス/コットンエンパイア/コットン empire.mobi http://download.bookset.me/d.php?f=2019/4/%5B 米国%5D スヴェン・ベケット - コットン・エンパイア - 9787513923927.mobi
この長いリストの各行は、Linuxシステムのコマンドラインインターフェイスに直接コピーすることで直接ダウンロードできます(booksフォルダーが必要です)。 しかし、bootset Webサイトのダウンロードサービスにはアンチクローラー対策があるため、ここでクレイジーにダウンロードすることはできませんが、レベルはそれほど高くなく、IPを制限と頻度を制限する**だけです。
1.各IPは、30を超えるファイルを連続してダウンロードすることはできません。
2.各IPの連続ダウンロードファイルの間隔は、10秒未満にすることはできません。
3. 10秒未満の場合、ダウンロードできるのは5つのファイルのみであり、6番目のファイルはIPのブロックを開始します。
自動リダイヤル
ダウンロードコードは簡単に記述できますが、これらの3つの制限を破るにはどうすればよいですか? 主なことはあなた自身のIPを変更することです。 そして、私は多数のダウンロード物なので、プロキシIPは実行可能ではありません、それは私のブロードバンドがパブリックネットワークIPを持っていることは非常に偶然です、私はIPを切り替えるためにリダイヤルするだけでよく、それは変装してブロックを突破します。
私が使用しているルーターはXiaomiルーターで、通常の状況では、リダイヤルにはバックグラウンドへの手動ログインが必要であり、最初に切断してから再接続する必要がありますが、自動化ツールは面倒すぎて手動で操作できません。
私は類人猿ブログで解決策を見つけ、pythonを使用してXiaomiルーターにログインし、リダイヤルしました。 このページのコードが長すぎて、前に提供されたダウンロードリンクの「mi.py」をここに貼り付けることができません。
コードはpython2を使用して実行され、自動リダイヤルとルーターの再起動の2つの機能しかありません。 リダイヤルするコマンドは次のとおりです。
python2 mi.py 192.168.31.1 <password> 再接続
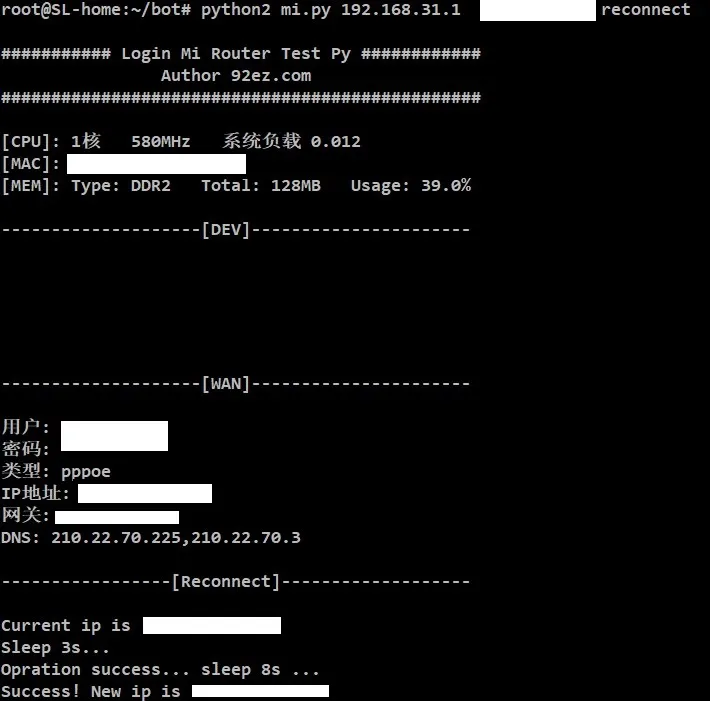
運用終了後、IPが切り替わり、この時点で好きなことができます。
P.S
私はここで奇妙なバグに遭遇しました、私は切断して再接続した直後にクローラーを起動することができません、さもなければ私は奇妙なドメイン名とタイムアウトに302ジャンプし続けます。
--2019-05-04 02:19:27-- http://download.bookset.me/d.php?f=2019/3/%E7%91%9E%C2%B7%E8%BE%BE%E5%88%A9%E6%AC%A7-%E5%80%BA%E5%8A%A1%E5%8D%B1%E6%9C%BA-9787521700077.azw3
download.bookset.me 解決しています(download.bookset.me)... 104.31.84.161、104.31.85.161、2606:4700:30::681f:55a1、...
download.bookset.me (download.bookset.me)への接続|104.31.84.161|:80... 接続。
HTTP 要求が送信されました。応答を待っています... 302 一時的に移動しました
場所:http://sh.cncmax.cn/ [下記]
--2019-05-04 02:19:27-- http://sh.cncmax.cn/
sh.cncmax.cn 解決しています(sh.cncmax.cn)... 210.51.46.116
sh.cncmax.cn への接続 (sh.cncmax.cn)|210.51.46.116|:80... 接続。
HTTP 要求が送信されました。応答を待っています... 302 一時的に移動しました
場所:http://sh.cncmax.cn/ [下記]
--2019-05-04 02:19:27-- http://sh.cncmax.cn/
sh.cncmax.cn への接続 (sh.cncmax.cn)|210.51.46.116|:80... 失敗: 接続がタイムアウトしました。
sh.cncmax.cn 解決しています(sh.cncmax.cn)... 210.51.46.116
sh.cncmax.cn への接続 (sh.cncmax.cn)|210.51.46.116|:80... 失敗: 接続がタイムアウトしました。
再試行。
--2019-05-04 02:23:50-- (トライ:2)http://sh.cncmax.cn/
sh.cncmax.cn への接続 (sh.cncmax.cn)|210.51.46.116|:80... 失敗: 接続がタイムアウトしました。
再試行。
このドメイン名を開くことはできません、私はwhoisをチェックしました、ドメイン名はユニコムに属しています、しかし国家ラジオテレビ管理局の文書では、このドメイン名に対応するサービスは「ブロードバンドマイワールド上海」です、これはオペレーターの幽霊であるべきだと思います。 これは中間者攻撃に相当し、ダウンロードサイトであっても誰もがhttpsを使用することを推奨しています。
一括ダウンロード
302のため、私のコードは2つの部分に分かれています。 最初の部分はダウンロードし、2番目の部分はダウンロードを終了し、IPを変更してダウンロードを再開します。
1.前の手順のデータはあまりきれいにクリーニングされておらず、一部の文字は冗長だったため、自動的にダウンロードするときに新しいフォルダーを作成するときにクローラーでエラーが発生するため、replaceを使用してそれらの中国語の英語記号をクリーンアップする必要がありました。
# コーディング: UTF-8
# !/usr/bin/python3
OS のインポート
システムのインポート
JSON をインポートする
インポート urllib.request
インポート再
インポート URLLIB
インポート時間
ランダムにインポート
数値 = 0
ファイル = オープン("数値.txt")
os.system('screen -X -S bookup quit ')
file.readlines()の行の場合:
数値 == 30 の場合:
os.system('cd /root/bot & screen -S bookup -d -m -- sh -c "python 2.py; 実行$SHELL"')
壊す
name = re.findall(r'/root/books/(.*?) http', line)
名前 = 名前[0]
name = name.replace(' ', "-")
name = name.replace('-', "")
name = name.replace('(', "")
name = name.replace(')', "")
name = name.replace(':', "-")
name = name.replace(':', "-")
name = name.replace('(', "")
name = name.replace(')', "")
name = name.replace('—', "-")
name = name.replace(',', ",")
name = name.replace('。 ', ".")
name = name.replace('! ', "")
name = name.replace('!', "")
name = name.replace('? ', "")
name = name.replace('?', "")
name = name.replace('【', "")
name = name.replace('】', "")
name = name.replace('"', "")
name = name.replace('"', "")
name = name.replace(''', "")
name = name.replace(''', "")
name = name.replace('"', "")
name = name.replace('\'', "")
name = name.replace('、', "-")
name1 = re.findall(r'^(.*?) /'、名前)
名前1 = 名前1[0]
os.system('mkdir /root/books/%s' % name1)
line1 =re.findall(r'http(.*?) $'、行)
ライン1 = ライン1[0]
数値 = 数値 + 1
link = 'wget --user-agent="Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (ヤモリのような KHTML) Version/11.0 Mobile/15A372 Safari/604.1" -O /root/books/'+name+" 'http"+line1+"'"
時間.睡眠(12)
システム(リンク)
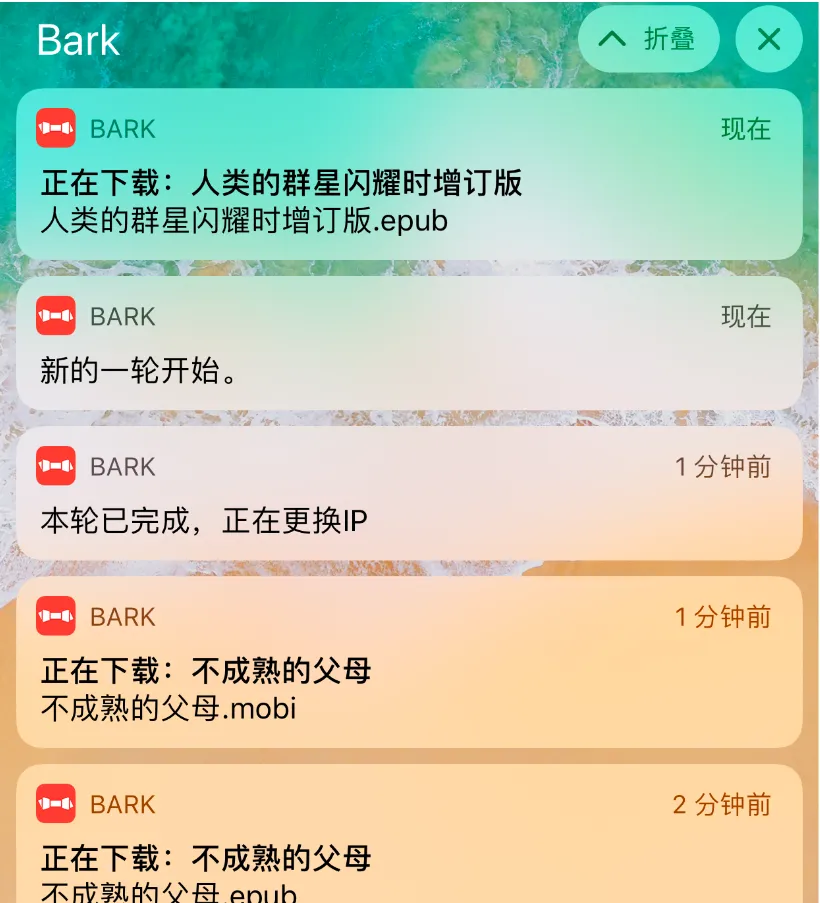
os.system("curl '<you-token>https://api.day.app//downloading:'"+name)
open('num.txt', 'r') を fin として使用します。
data = fin.read().splitlines(true)
open('num.txt', 'w') を fout として使用します。
fout.writelines(data[1:])
スクリプトの機能は、num .txtを行単位で読み取り、12秒待ってからファイルをダウンロードし、読み取った行を削除し、リサイクルし、30行ダウンロードし、別のスクリプトを開始して終了し、最後にBarkのプッシュサービスを使用して、問題が発生した場合は、特定のファイルを見つけてスクリプトを再起動できるようにします。
*主な問題は302ジャンプです。 *
2. この部分の機能は、スクリプト 1 の実行を終了し、'time.sleep' を 1 分間リダイヤルし、スクリプト 1 を開始することです。
# コーディング: UTF-8
# !/usr/bin/python3
OS のインポート
システムのインポート
インポート時間
os.system('screen -X -S bookdown quit ')
os.system("curl '<you-token>https://api.day.app//round が完了し、IP交換が行われています")
os.system("python2 mi.py 192.168.31.1 <password> reconnect")
睡眠時間(60)
os.system("curl 'https://api.day.app/<you-token>/start of a new round." ")
os.system('cd /root/bot & screen -S bookdown -d -m -- sh -c "python 1.py; 実行$SHELL"')
screenを使用する利点は、バックグラウンドで実行でき、スクリプトがハングすることを心配する必要がなく、sshアップしてエラーメッセージを表示することもできることです。
ダウンロードを開始するには、次のコードを使用します。
screen -S bookdown -d -m -- sh -c "python 1.py; エグゼクティブ$SHELL」
起動すると、1.py と 2.py は、ファイルが数.txt空になるまで永久機関のように実行されます。
# 追記
ホイールを作るのは楽しいです、いくつかの本もとても良いです、この記事が完成したとき、私はすべてのデータをダウンロードしておらず、約半分しかダウンロードしておらず、完全なダウンロードを完了するのに22時間かかると予想されます。 これらのうち、2.5時間は切断されたリダイヤルであり、15時間はtime.sleepです。
実際、コードは単純化することができ、defを学ぶとき、私は2つのスクリプトを必要としません...
タグ :
著作権に関する注意事項 :
この記事はSaltyLeoによって書かれました。誤りがある場合は、コメントでフィードバックをお願いします。この記事の転載や引用を行う場合は、CC BY-NC-SA ライセンスに従う必要があります。帰属表示、非営利利用、同一条件の共有が必要です!コメント :
続きを読む :


自分でコードを書いて、一般的ではない問題を解決します。

この記事では、単純なマルチレベル プロキシの状況でビジター IP を取得するために使用できる nginx プラグイン nginxhttprealip_module を紹介します。

ただし、これらは一時的なもので、再起動すると失敗し、設定前の状態に戻ります。
ストアダウンロード版のソフトウェアフラッシュバック問題を解決
未開発の機能はまだまだたくさんありますが、まだまだ先を急いでいます。多くのことは個人の意志に依存しません。
 日本語
日本語 中文
中文 English
English Français
Français Deutsch
Deutsch Pу́сский язы́к
Pу́сский язы́к 한국어
한국어 Español
Españolサイト情報
タグ: 203
総ページビュー数: 12,890,324
読み込み時間: 15.5 ms
Ver : 4.0.1