Python crawler advanced: innovador sistema anti-crawler
04 de May de 2019 · 1003 · 25 minSoy un coleccionista y quiero recopilar buenos recursos, pero es demasiado lento y laborioso descargarlos uno por uno, así que tengo la anterior [API y rastreador] (http://tstrs.me/1447.html), pero ahora los webmasters están eliminando gradualmente las restricciones de derechos de autor, por lo que no solo analizo los enlaces de archivos, quiero guardarlos en mi propio disco duro.
Más tarde, creé un disco en la nube [TSTR_Cloud] (https://cloud.tstrs.me) para compartir. A menudo camino por el río, ¿cómo no puedo mojarme los zapatos, mi disco de nube también está siendo rastreado por rastreadores, tengo que privatizarlo, necesito usar una contraseña para acceder?
Pero todavía estoy raspando libros electrónicos de diferentes sitios y guardándolos, que actualmente son 52G, alrededor de 5300 copias.

El contenido principal de este artículo son estrategias anti-crawler y consejos anti-crawler.
# Anti-rastreador
Las medidas anti-rastreo actuales son de fácil a difícil:
IP
Surge un tráfico de dirección IP y la IP se bloquea de manera específica.
UserAgent
Identificar useragents no humanos, bloqueados, por ejemplo, JavaClient 1.6
frecuencia
Según la frecuencia de acceso de una determinada IP, el acceso es demasiado frecuente en la unidad de tiempo, bloqueado.
Captcha
Se requiere un captcha para obtener datos.
Cifrado JS
JS-cifrar los datos.
cookie
Debe iniciar sesión en su cuenta para rastrear.
Todo lo anterior se basa en la experiencia de otros grandes, y solo me he encontrado con los tres primeros hasta ahora.
# Anti-anti-crawler
IP proxy
Utilice IP proxy para reducir la probabilidad de identificar bloques basados en IP.
Simular el agente de usuario
El uso de un agente de usuario como "Mozilla / 5.0" reduce la probabilidad de rechazo de un sitio web.
Sueño programado
Toma una página y luego tómala al azar durante 2-5 segundos.
Plataforma de reconocimiento o recepción de códigos Captcha
Utilice el código de verificación para identificar o utilice la plataforma receptora de códigos para identificar el código de verificación.
PhantomJS,Selenio
Use el marco de rastreo que viene con el navegador para rastrear la página, sin importar cuán complejo sea el cifrado, el navegador lo decodificará por usted.
Cuentas masivas
Cree una gran cantidad de cookies con cuentas falsas para que las usen los rastreadores.
# Práctica
Escribiendo aquí, algunas personas definitivamente dirán que estoy remando, * realmente no hay ah *, la sinopsis anterior no se puede ampliar si el contenido no está claramente escrito, el siguiente es un rastreador que hice recientemente, lleno de productos secos.
Todo el código utilizado en este artículo: {% btn https://cloud.tstrs.me/?/%E7%A8%80%E6%9C%89%E8%B5%84%E6%BA%90/%E7%88%AC%E8%99%AB/bookset.me/, descarga de código, descarga fa-lg fa-fw %}
Análisis de objetivos
El objetivo de este rastreo es bookset.me, que es un sitio web de libros electrónicos con nuevas actualizaciones de libros, el backend es WordPress + PHP, y los enlaces a la página de detalles también son muy regulares, como:
https://bookset.me/6647.html
Abrir el enlace es *Lo que los filósofos están pensando Yang Novel (autor) *, los libros de esta web desde hace más de medio año son tres versiones coexistentes, mobi+epub+azw3 por lo que, específico para un solo enlace de descarga de archivo es:
http://download.bookset.me/d.php?f=2017/10/ Novela Yang - Lo que piensan los filósofos - 9787559609939.epub
¿No es muy regular? Mientras haya regularidad, puedes escalar.
Requisitos
Sección de hardware:
Un servidor Linux
Banda ancha IP IP pública
Router Xiaomi (si es de otra marca, el código no garantiza que funcione correctamente)
Sección de software:
pantalla
Python 2 y Python 3 (a menos que se indique lo contrario, el siguiente código se ejecuta en Python 3)
Diagrama de flujo
Rastrear enlaces de descarga
Debido a que el enlace de descarga y el sitio principal están separados, por lo que puede encontrar diferentes estrategias anti-rastreador, por razones de seguridad, la solución que elegí es rastrear primero todos los enlaces de descarga y luego descargarlos en lotes, y usar el siguiente código para rastrear los enlaces de descarga de todos los libros electrónicos de la página 1 a 133 y guardarlos en el mismo número de carpeta.txt:
# Codificación: UTF-8
# !/usr/bin/python3
Importar sistema operativo
Importar sys
Importar JSON
importar urllib.request
Importar re
Importar urllib
Tiempo de importación
Para la lista1 en el intervalo(1,133,1):
números = []
url = r'https://bookset.me/page/%s' % list1
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/55.0.2883.87 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
number = re.findall(r'<h3><a href="(.+?)" alt="', html)
numbers.extend(número)
Para páginas en números:
url = r'%s' % páginas
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/55.0.2883.87 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
dlinks = re.findall(r'd.php(.+?) mbm-book-download-links-text', html)
name = re.findall(r</small>' <span class="muted">(.+?)'</span>, html)
nombre = nombre[0]
dlinks1 = []
tipo = []
Para p en dlinks:
sx1 = p.replace('"><span class="', "")
sx2 = sx1[-5:]
dlinks1.append(sx1)
tipo.anexar(sx2)
Para (dlinks2, type1) en zip(dlinks1, type):
imprimir(nombre)
links = 'wget --user-agent="Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 como Mac OS X) AppleWebKit/604.1.38 (KHTML, como Gecko) Versión/11.0 Móvil/15A372 Safari/604.1" -O /root/books/' + nombre + '/' + nombre + type1 + ' http://download.bookset.me/d.php' + dlinks2
fileObject = open('num.txt', 'a')
fileObject.write(enlaces)
fileObject.write('\n')
fileObject.close()
Si eres demasiado perezoso para rastrear, puedes descargar directamente los archivos que he rastreado aquí: {% btn https://cloud.tstrs.me/?/%E7%A8%80%E6%9C%89%E8%B5%84%E6%BA%90/%E7%88%AC%E8%99%AB/bookset.me/bookset.me-2019-04-28.txt, descargar, descargar fa-lg FA-FW %}
Este archivo se abre en este formato:
wget --user-agent="Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 como Mac OS X) AppleWebKit/604.1.38 (KHTML, como Gecko) Versión/11.0 Mobile/15A372 Safari/604.1" -O /root/books/Cotton Empire/Cotton Empire.epub http://download.bookset.me/d.php?f=2019/4/%5B %5D Sven Beckett-Cotton Empire-9787513923927.epub
wget --user-agent="Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 como Mac OS X) AppleWebKit/604.1.38 (KHTML, como Gecko) Versión/11.0 Móvil/15A372 Safari/604.1" -O /root/books/Cotton Empire/Cotton Empire.azw3 http://download.bookset.me/d.php?f=2019/4/%5B %5D Sven Beckett-Cotton Empire-9787513923927.azw3
wget --user-agent="Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 como Mac OS X) AppleWebKit/604.1.38 (KHTML, como Gecko) Versión/11.0 Móvil/15A372 Safari/604.1" -O /root/books/cotton empire/cotton empire.mobi http://download.bookset.me/d.php?f=2019/4/%5B U.S. %5D Sven Beckett - Imperio del algodón - 9787513923927.mobi
Cada línea de esta larga lista se puede descargar directamente copiándola directamente a la interfaz de línea de comandos del sistema Linux (requiere la carpeta de libros). Pero no puedes descargar loco aquí, porque el servicio de descarga del sitio web de arranque tiene medidas anti-rastreador, pero el nivel no es muy alto, solo limitar IP y limitar frecuencia.
1. Cada IP no puede descargar más de 30 archivos consecutivamente.
2. El intervalo entre los archivos de descarga continua de cada IP no puede ser inferior a 10s.
3. Si es menos de 10s, solo se pueden descargar 5 archivos, y el sexto comenzará a bloquear la IP.
Rellamada automática
El código de descarga es fácil de escribir, pero ¿cómo romper estas tres limitaciones? Lo principal es modificar su propia IP. Y soy una gran cantidad de cosas de descarga, por lo que la IP proxy no es factible, es muy coincidencia que mi banda ancha tenga una IP de red pública, solo necesito volver a marcar para cambiar la IP, y rompe el bloque disfrazado.
El enrutador que uso es un enrutador Xiaomi, en circunstancias normales, volver a marcar requiere inicio de sesión manual en segundo plano, desconectarse primero y luego volver a conectarse, pero la herramienta de automatización es demasiado problemática para operar manualmente.
Encontré una solución en el blog [de un simio] (https://www.92ez.com), iniciando sesión en el enrutador Xiaomi usando python y volviendo a marcar. El código es demasiado largo en esta [página] (https://www.92ez.com/?action=show&id=23405) para pegar aquí, 'mi.py' en el enlace de descarga proporcionado anteriormente.
El código se ejecuta usando python2 y tiene solo dos funciones, remarcar automáticamente y reiniciar el enrutador. El comando para volver a marcar es:
python2 mi.py 192.168.31.1 <password> reconectar
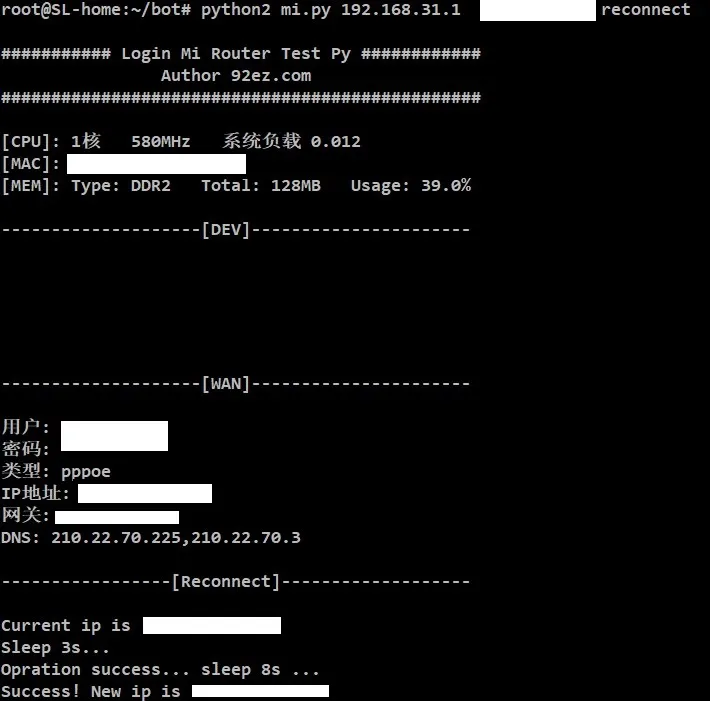
Después del final de la operación, la IP se cambia, y en este momento puede hacer lo que quiera.
P.S
Me encontré con un error extraño aquí, no puedo iniciar el rastreador inmediatamente después de desconectarme y volver a conectarme, de lo contrario seguiré recibiendo 302 saltos a un nombre de dominio extraño y tiempo de espera.
--2019-05-04 02:19:27-- http://download.bookset.me/d.php?f=2019/3/%E7%91%9E%C2%B7%E8%BE%BE%E5%88%A9%E6%AC%A7-%E5%80%BA%E5%8A%A1%E5%8D%B1%E6%9C%BA-9787521700077.azw3
Resolviendo download.bookset.me (download.bookset.me)... 104.31.84.161, 104.31.85.161, 2606:4700:30::681f:55a1, ...
Conectando a download.bookset.me (download.bookset.me)|104.31.84.161|:80... conexo.
Solicitud HTTP enviada, en espera de respuesta... 302 Trasladado temporalmente
Ubicación: http://sh.cncmax.cn/ [siguiente]
--2019-05-04 02:19:27-- http://sh.cncmax.cn/
Resolviendo sh.cncmax.cn (sh.cncmax.cn)... 210.51.46.116
Conectando a sh.cncmax.cn (sh.cncmax.cn)|210.51.46.116|:80... conexo.
Solicitud HTTP enviada, en espera de respuesta... 302 Trasladado temporalmente
Ubicación: http://sh.cncmax.cn/ [siguiente]
--2019-05-04 02:19:27-- http://sh.cncmax.cn/
Conectando a sh.cncmax.cn (sh.cncmax.cn)|210.51.46.116|:80... error: se agotó el tiempo de espera de la conexión.
Resolviendo sh.cncmax.cn (sh.cncmax.cn)... 210.51.46.116
Conectando a sh.cncmax.cn (sh.cncmax.cn)|210.51.46.116|:80... error: se agotó el tiempo de espera de la conexión.
Reintentando.
--2019-05-04 02:23:50-- (prueba: 2) http://sh.cncmax.cn/
Conectando a sh.cncmax.cn (sh.cncmax.cn)|210.51.46.116|:80... error: se agotó el tiempo de espera de la conexión.
Reintentando.
Este nombre de dominio no se puede abrir, comprobé whois, el nombre de dominio pertenece a Unicom, pero en un [documento] (http://www.sarft.gov.cn/shanty/resource/appendix/2008/07/03/20080711145144410222.doc) de la Administración Estatal de Radio y Televisión, el servicio correspondiente a este nombre de dominio es 'Broadband My World Shanghai', creo que este debería ser el fantasma del operador. Esto es equivalente a un ataque man-in-the-middle, y se recomienda que todos usen https incluso si se trata de un sitio de descarga.
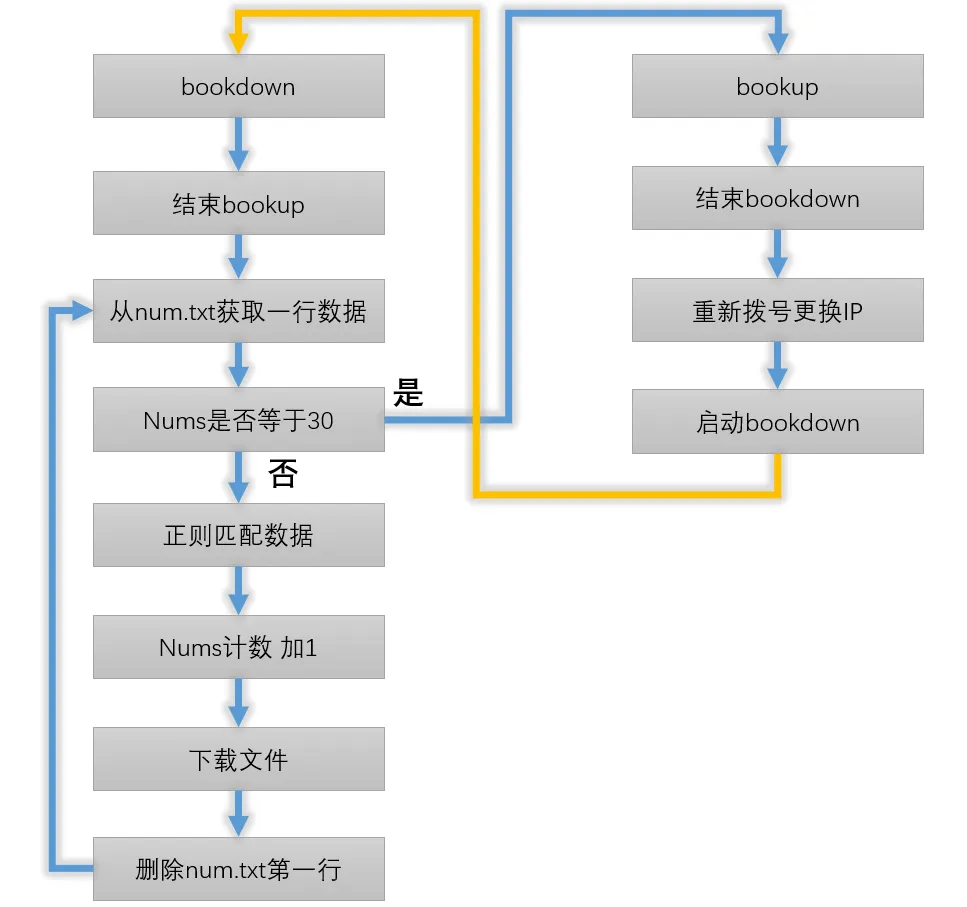
Descarga por lotes
Debido a 302, mi código se divide en dos partes. La primera parte se descarga, la segunda parte finaliza la descarga, cambia la IP y comienza la descarga nuevamente.
1.Debido a que los datos de mis pasos anteriores no se limpiaron muy y algunos caracteres eran redundantes, el rastreador tendría errores al crear nuevas carpetas al descargar automáticamente, por lo que fue necesario usar reemplazar para limpiar esos símbolos chinos en inglés.
# Codificación: UTF-8
# !/usr/bin/python3
Importar sistema operativo
Importar sys
Importar JSON
importar urllib.request
Importar re
Importar urllib
Tiempo de importación
Importar aleatoriamente
nums = 0
archivo = abrir("num.txt")
os.system('screen -X -S bookup quit ')
para línea en file.readlines():
if nums == 30:
os.system('cd /root/bot && screen -S bookup -d -m -- sh -c "python 2.py; ejecutivo $SHELL"')
quebrar
name = re.findall(r'/root/books/(.*?) http', line)
nombre = nombre[0]
name = name.replace(' ', "-")
name = name.replace('-', "")
name = name.replace('(', "")
name = name.replace(')', "")
name = name.replace(':', "-")
name = name.replace(':', "-")
name = name.replace('(', "")
name = name.replace(')', "")
name = name.replace('—', "-")
name = name.replace(',', ",")
name = name.replace('。 ', ".")
name = name.replace('! ', "")
name = name.replace('!', "")
name = name.replace('? ', "")
name = name.replace('?', "")
name = name.replace('【', "")
name = name.replace('】', "")
name = name.replace('"', "")
name = name.replace('"', "")
name = nombre.reemplazar(''', "")
name = nombre.reemplazar(''', "")
name = name.replace('"', "")
name = name.replace('\'', "")
name = name.replace('、', "-")
name1 = re.findall(r'^(.*?) /', nombre)
nombre1 = nombre1[0]
os.system('mkdir /root/books/%s' % name1)
line1 =re.findall(r'http(.*?) $', línea)
línea1 = línea1[0]
nums = nums + 1
link = 'wget --user-agent="Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 como Mac OS X) AppleWebKit/604.1.38 (KHTML, como Gecko) Versión/11.0 Móvil/15A372 Safari/604.1" -O /root/books/'+name+" 'http"+line1+"'"
tiempo.dormir(12)
os.system(enlace)
os.system("curl '<you-token>https://api.day.app//downloading:'"+name)
con open('num.txt', 'r') como fin:
data = fin.read().splitlines(True)
con open('num.txt', 'w') como fout:
fout.writelines(data[1:])
La función del script es leer num .txt por línea, esperar 12 segundos, descargar el archivo, eliminar la línea que se leyó, reciclar, descargar 30 seguidos, iniciar otro script y salir, y finalmente uso el servicio push de Bark, para que si hay un problema, pueda localizar el archivo específico y reiniciar el script.
*El principal problema es el salto 302. *
2. La función de esta parte es finalizar la ejecución del script 1, volver a marcar, 'time.sleep' durante un minuto e iniciar el script 1.
# Codificación: UTF-8
# !/usr/bin/python3
Importar sistema operativo
Importar sys
Tiempo de importación
os.system('screen -X -S bookdown quit ')
os.system("curl '<you-token>https://api.day.app//round completado, se está realizando un reemplazo de IP")
os.system("python2 mi.py 192.168.31.1 <password> reconectar")
tiempo.dormir(60)
os.system("curl 'https://api.day.app/<you-token>/inicio de una nueva ronda.") ")
os.system('cd /root/bot && screen -S bookdown -d -m -- sh -c "python 1.py; ejecutivo $SHELL"')
La ventaja de usar la pantalla es que puede ejecutarse en segundo plano, no hay necesidad de preocuparse de que el script se cuelgue, y también puede ssh up para ver el mensaje de error.
Para iniciar la descarga, utilice el código siguiente:
screen -S bookdown -d -m -- sh -c "python 1.py; $SHELL ejecutivo"
Una vez iniciados 1.py y 2.py funcionan como máquinas de movimiento perpetuo hasta que los archivos están vacíos en el .txt.
# Posdata
Es divertido hacer ruedas, algunos libros también son muy buenos, cuando se completó este artículo, no había descargado todos los datos, solo la mitad descargué, y se espera que tome 22 horas completar la descarga completa. De estos, 2,5 horas son rellamadas desconectadas y 15 horas son tiempo.sueño.
De hecho, el código se puede simplificar, y cuando aprendo def, no necesito dos scripts ...
reference
Etiquetas :
Aviso de derechos de autor :
Este artículo está escrito por SaltyLeo. Si hay algún error en el contenido, por favor, deje un comentario. Al copiar o citar este artículo, por favor, cumpla con la licencia CC BY-NC-SA que requiere atribución, uso no comercial y compartir bajo la misma licencia.Comentario :
Leer más :


Recientemente, el tema de mi blog se actualizó y WordPress me solicitó que lo actualizara, pero se me indicó que la actualización no se pudo completar debido a permisos insuficientes.

Este artículo le dirá cómo instalar V2ray sin acceder a github
La función más importante de una computadora inactiva con bajo consumo de energía como una computadora portátil es descargar películas las 24 horas del día, y después de configurar el ddns, la red externa también puede verificar el progreso de la descarga, agregar nuevas semillas, etc.
Diseñar y construir un robot de búsqueda de libros electrónicos basado en Telegram

Una computadora que actúa como un servidor genera automáticamente una pregunta para que el usuario la responda. Esta pregunta puede ser generada y juzgada por una computadora, pero solo un humano puede responderla.
Tabla de contenidos
Populares
 Español
Español 中文
中文 English
English Français
Français Deutsch
Deutsch 日本語
日本語 Pу́сский язы́к
Pу́сский язы́к 한국어
한국어Información del sitio
Etiquetas: 221
Vistas totales de página: 12,931,942
tiempo de carga: 7.04 ms
Ver : 3.0.1